당신은 온라인 연습 문제를 통해 Microsoft 70-767 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 70-767 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 136개의 시험 문제와 답을 포함하십시오.
/ 4
Question No : 1
You need to ensure that a downstream system can consume data in a Master Data Services (MDS) system.
What should you configure?
정답: Explanation:
Subscription views to consume your master data.
References: https://docs.microsoft.com/en-us/sql/master-data-services/master-data-services-overview-mds?view=sql-server-2017
Question No : 2
HOTSPOT
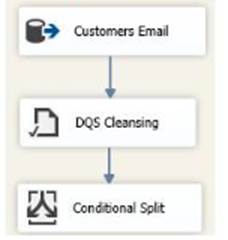
You have a Microsoft SQL Server Integration Services (SSIS) package that contains a Data Flow task as shown in the Data Flow exhibit. (Click the Exhibit button.)
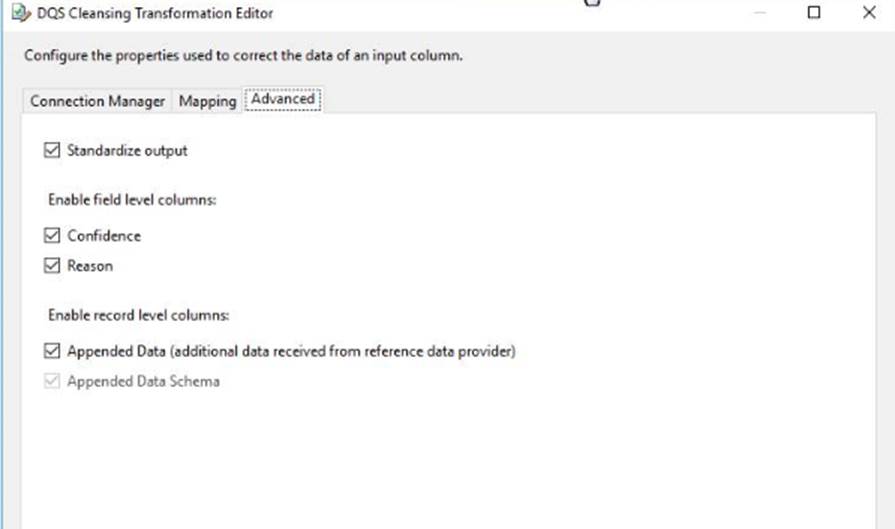
You install Data Quality Services (DQS) on the same server that hosts SSIS and deploy a knowledge base to manage customer email addresses. You add a DQS Cleansing transform to the Data Flow as shown in the Cleansing exhibit. (Click the Exhibit button.)
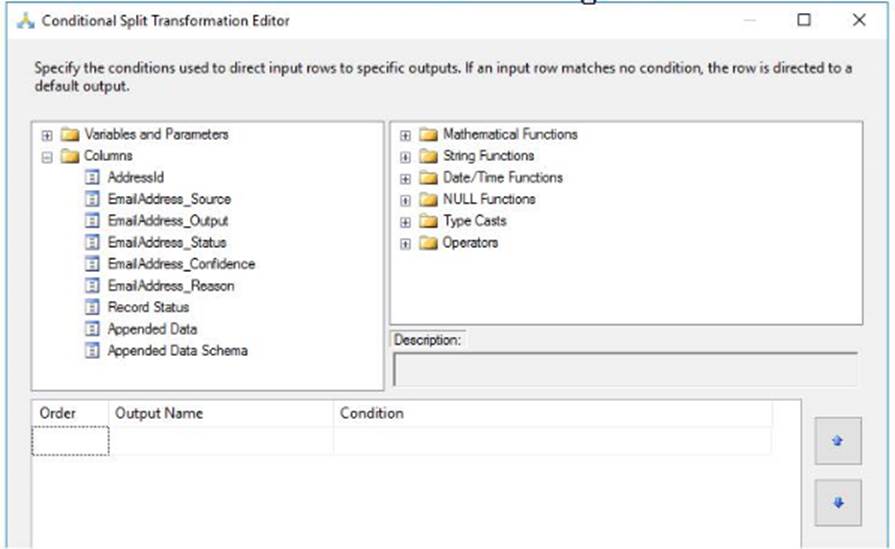
You create a Conditional Split transform as shown in the Splitter exhibit. (Click the Exhibit button.)
You need to split the output of the DQ5 Cleansing task to obtain only Correct values from the EmailAddress column. For each of the following statements, select Yes if the statement is true. Otherwise, select No.
정답:
Question No : 3
You have a server that has Data Quality Services (DQS) installed.
You create a matching policy that contains one matching rule.
You need to configure the Similarity of Similar percentage that defines a match.
Which similarity percentage will always generate a similarity score of 0?
정답: Explanation:
The minimum similarity between the values of a field is 60%. If the calculated matching score for a field of two records is less than 60, the similarity score is automatically set to 0.
References: https://docs.microsoft.com/en-us/sql/data-quality-services/create-a-matching-policy?view=sql-server-2017
Question No : 4
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft SQL server that has Data Quality Services (DQS) installed. You need to review the completeness and the uniqueness of the data stored in the matching policy. Solution: You modify the weight of the domain in the matching rule.
Does this meet the goal?
정답: Explanation:
Use a matching rule, and use completeness and uniqueness data to determine what weight to give a field in the matching process.
If there is a high level of uniqueness in a field, using the field in a matching policy can decrease the matching results, so you may want to set the weight for that field to a relatively small value. If you have a low level of uniqueness for a column, but low completeness, you may not want to include a domain for that column.
References: https://docs.microsoft.com/en-us/sql/data-quality-services/create-a-matching-policy?view=sql-server-2017
Question No : 5
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft SQL server that has Data Quality Services (DQS) installed.
You need to review the completeness and the uniqueness of the data stored in the matching policy.
Solution: You create a matching rule.
Does this meet the goal?
정답: Explanation:
Use a matching rule, and use completeness and uniqueness data to determine what weight to give a field in the matching process.
If there is a high level of uniqueness in a field, using the field in a matching policy can decrease the matching results, so you may want to set the weight for that field to a relatively small value. If you have a low level of uniqueness for a column, but low completeness, you may not want to include a domain for that column.
References: https://docs.microsoft.com/en-us/sql/data-quality-services/create-a-matching-policy?view=sql-server-2017
Question No : 6
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft SQL server that has Data Quality Services (DQS) installed.
You need to review the completeness and the uniqueness of the data stored in the matching policy.
Solution: You profile the data.
Does this meet the goal?
정답: Explanation:
Use a matching rule.
References: https://docs.microsoft.com/en-us/sql/data-quality-services/create-a-matching-policy?view=sql-server-2017
Question No : 7
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
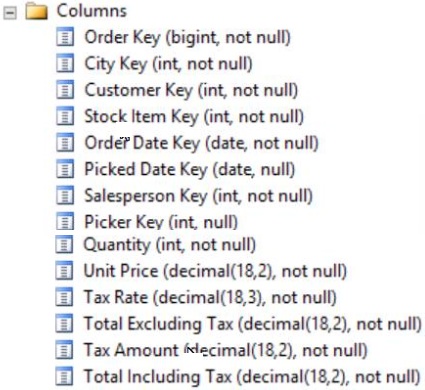
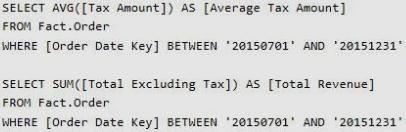
Your company uses Microsoft SQL Server to deploy a data warehouse to an environment that has a SQL Server Analysis Services (SSAS) instance. The data warehouse includes the Fact.Order table as shown in the following table definition. The table has no indexes.
You must minimize the amount of space that indexes for the Fact.Order table consume. You run the following queries frequently. Both queries must be able to use a columnstore index:
You need to ensure that the queries complete as quickly as possible.
Solution: You create one columnstore index that includes the [Order Date Key], [Tax Amount], and [Total Excluding Tax] columns.
Does the solution meet the goal?
정답: Explanation:
You should use a columnstore index.
Columnstore indexes are the standard for storing and querying large data warehousing fact tables. This index uses column-based data storage and query processing to achieve gains up to 10 times the query performance in your data warehouse over traditional row-oriented storage.
References: https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview?view=sql-server-2017
Question No : 8
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
Your company uses Microsoft SQL Server to deploy a data warehouse to an environment that has a SQL Server Analysis Services (SSAS) instance. The data warehouse includes the Fact.Order table as shown in the following table definition. The table has no indexes.
You must minimize the amount of space that indexes for the Fact.Order table consume. You run the following queries frequently. Both queries must be able to use a columnstore index:
You need to ensure that the queries complete as quickly as possible.
SolutionvYou create two nonclustered indexes. The first includes the [Order Date Key] and [Tax Amount] columns. The second will include the [Order Date Key] and [Total Excluding Tax] columns.
Does the solution meet the goal?
정답:
Question No : 9
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
Your company uses Microsoft SQL Server to deploy a data warehouse to an environment that has a SQL Server Analysis Services (SSAS) instance. The data warehouse includes the Fact.Order table as shown in the following table definition. The table has no indexes.
You need to ensure that the queries complete as quickly as possible.
Solution: You create measure for the Fact.Order table. Does the solution meet the goal?
정답: Explanation:
You should use a columnstore index.
Columnstore indexes are the standard for storing and querying large data warehousing fact tables. This index uses column-based data storage and query processing to achieve gains up to 10 times the query performance in your data warehouse over traditional row-oriented storage.
References: https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview?view=sql-server-2017
Question No : 10
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
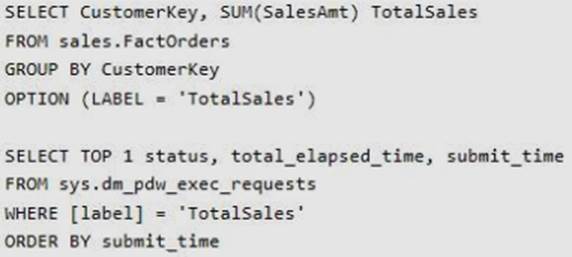
You have a Microsoft Azure SQL Data Warehouse instance. You run the following Transact-SQL statement:
The query fails to return results.
You need to determine why the query fails.
Solution: You run the following Transact-SQL statement:
Does the solution meet the goal?
정답: Explanation:
To use submit_time we must use sys.dm_pdw_exec_requests table.
References: https://docs.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-exec-requests-transact-sql?view=aps-pdw-2016-au7
Question No : 11
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure SQL Data Warehouse instance. You run the following Transact-SQL statement:
The query fails to return results.
You need to determine why the query fails.
Solution: You run the following Transact-SQL statements:
Does the solution meet the goal?
정답: Explanation:
We must use Label, not QueryID in the WHERE clause.
References: https://docs.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-exec-requests-transact-sql?view=aps-pdw-2016-au7
Question No : 12
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to deploy a Microsoft SQL server that will host a data warehouse named DB1.
The server will contain four SATA drives configured as a RAID 10 array.
You need to minimize write contention on the transaction log when data is being loaded to the database.
Solution: You configure the server to automatically delete the transaction logs nightly.
Does this meet the goal?
정답: Explanation:
You should place the log file on a separate drive.
References:
https://www.red-gate.com/simple-talk/sql/database-administration/optimizing-transaction-log-throughput/
https://docs.microsoft.com/en-us/sql/relational-databases/policy-based-management/place-data-and-log-files-on-separate-drives?view=sql-server-2017
Question No : 13
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to deploy a Microsoft SQL server that will host a data warehouse named DB1.
The server will contain four SATA drives configured as a RAID 10 array.
You need to minimize write contention on the transaction log when data is being loaded to the database.
Solution: You add more data files to DB1.
Does this meet the goal?
정답: Explanation:
There is no performance gain, in terms of log throughput, from multiple log files. SQL Server does not write log records in parallel to multiple log files.
Instead you should place the log file on a separate drive.
References:
https://www.red-gate.com/simple-talk/sql/database-administration/optimizing-transaction-log-throughput/
https://docs.microsoft.com/en-us/sql/relational-databases/policy-based-management/place-data-and-log-files-on-separate-drives?view=sql-server-2017
Question No : 14
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to deploy a Microsoft SQL server that will host a data warehouse named DB1.
The server will contain four SATA drives configured as a RAID 10 array.
You need to minimize write contention on the transaction log when data is being loaded to the database.
Solution: You replace the SATA disks with SSD disks.
Does this meet the goal?
정답: Explanation:
A data warehouse is too big to store on an SSD.
Instead you should place the log file on a separate drive.
References:
https://docs.microsoft.com/en-us/sql/relational-databases/policy-based-management/place-data-and-log-files-on-separate-drives?view=sql-server-2017
Question No : 15
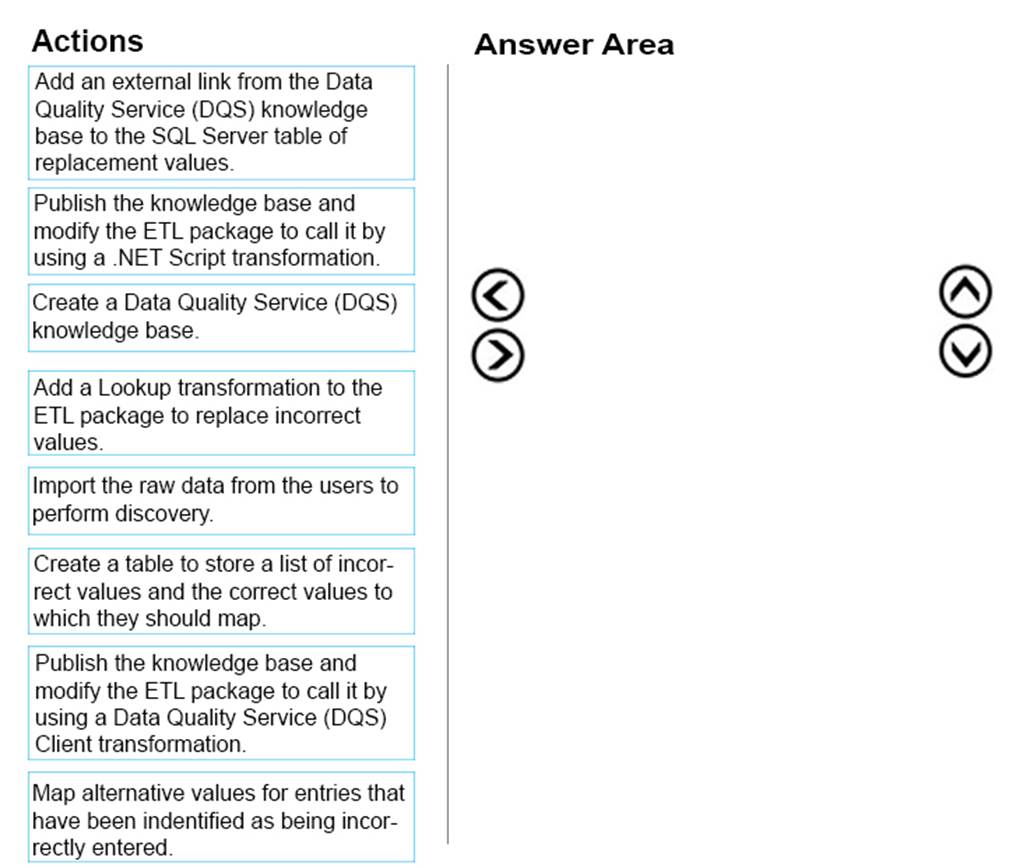
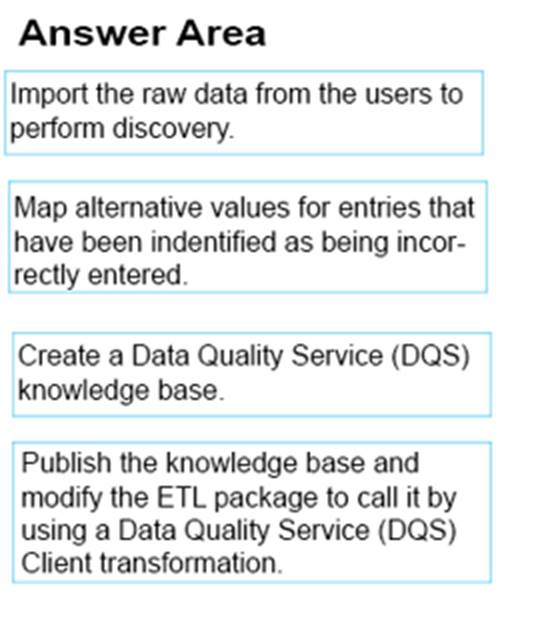
DRAG DROP
You have a series of analytic data models and reports that provide insights into the participation rates for sports at different schools. Users enter information about sports and participants into a client application. The application stores this transactional data in a Microsoft SQL Server database. A SQL Server Integration Services (SSIS) package loads the data into the models.
When users enter data, they do not consistently apply the correct names for the sports. The following table shows examples of the data entry issues.
You need to improve the quality of the data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.