Perform Data Engineering on Microsoft Azure HDInsight 온라인 연습
최종 업데이트 시간: 2025년03월22일
당신은 온라인 연습 문제를 통해 Microsoft 70-775 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 70-775 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 61개의 시험 문제와 답을 포함하십시오.
/ 2
Question No : 1
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are implementing a batch processing solution by using Azure HDInsight.
You plan to import 300 TB of data.
You plan to use one job that has many concurrent tasks to import the data in memory.
You need to maximize the amount of concurrent tasks for the job.
What should you do?
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is
independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are implementing a batch processing solution by using Azure HDInsight.
You have data stored in Azure.
You need to ensure that you can access the data by using Azure Active Directory (Azure AD) identities.
What should you do?
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are implementing a batch processing solution by using Azure HDInsight.
You have a table that contains sales data.
You plan to implement a query that will return the number of orders by zip code.
You need to minimize the execution time of the queries and to maximize the compression level of the resulting data.
What should you do?
정답:
Question No : 4
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are implementing a batch processing solution by using Azure HDInsight.
You need to integrate Apache Sqoop data and to chain complex jobs. The data and the jobs will implement MapReduce.
What should you do?
DRAG DROP
You are evaluating the use of Azure HDInsight clusters for various workloads.
Which type of HDInsight cluster should you create for each workload? To answer, drag the appropriate cluster types to the correct workloads. Each cluster type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
DRAG DROP
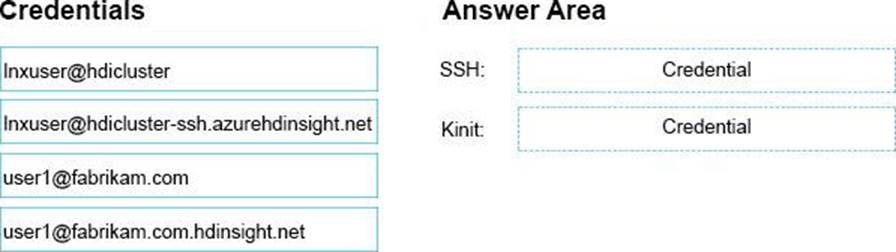
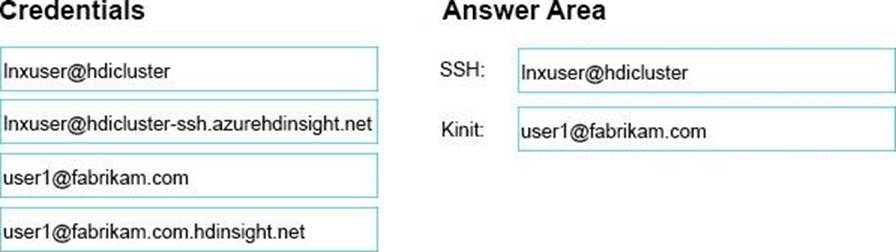
You have a domain-joined Apache Hadoop cluster in Azure HDInsight named hdicluster. The Linux account for hdicluster is named Inxuser. Your Active Directory account is named [email protected].
You need to run Hadoop commands from an SSH session.
Which credentials should you use? To answer, drag the appropriate credentials to the correct commands. Each credential may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
You have an Apache Hadoop cluster in Azure HDInsight that has a head node and three data
nodes. You have a MapReduce job. You receive a notification that a data node failed. You need to identify which component cause the failure.
Which tool should you use?
정답:
Question No : 8
DRAG DROP
You have a domain-joined Azure HDInsight cluster.
You plan to assign permissions to several support staff.
You need to assign roles to the staff so that they can perform specific tasks. The solution must use the principle of least privilege.
Which role should you assign for each task? To answer, drag the appropriate roles to the correct targets. Each role may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
정답:
Question No : 9
You have an Azure HDInsight cluster.
You need to store data in a file format that maximizes compression and increases read performance.
Which type of file format should you use?
HOTSPOT
You install the Microsoft Hive ODBC Driver on a computer that runs Windows 10 and has the 64bit version of Microsoft Office 2016 installed.
You deploy a new Apache Interactive Hive cluster in Azure HDInsight. The cluster is hosted at myHDICluster.azurehdinsight.net and contains a Hive table name hivesampletable that has 200,000 rows.
You plan to use HiveQL exclusively for the queries. The queries will return from 6,000 to 10,000 rows 90 percent of the time.
You need to configure a data source to ensure that you can use Microsoft Excel to access the data. The solution must ensure that the Hive queries execute as quickly as possible.
How should you configure the Advanced Options from the Microsoft Hive ODBC Driver DSN Setup dialog box? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You are configuring the Hive views on an Azure HDInsight cluster that is configured to use Kerberos. You plan to use the YARN logs to troubleshoot a query that runs against Apache Hadoop. You need to view the method, the service, and the authenticated account used to run the query.
Which method call should you view in the YARN logs?
정답:
Question No : 12
DRAG DROP
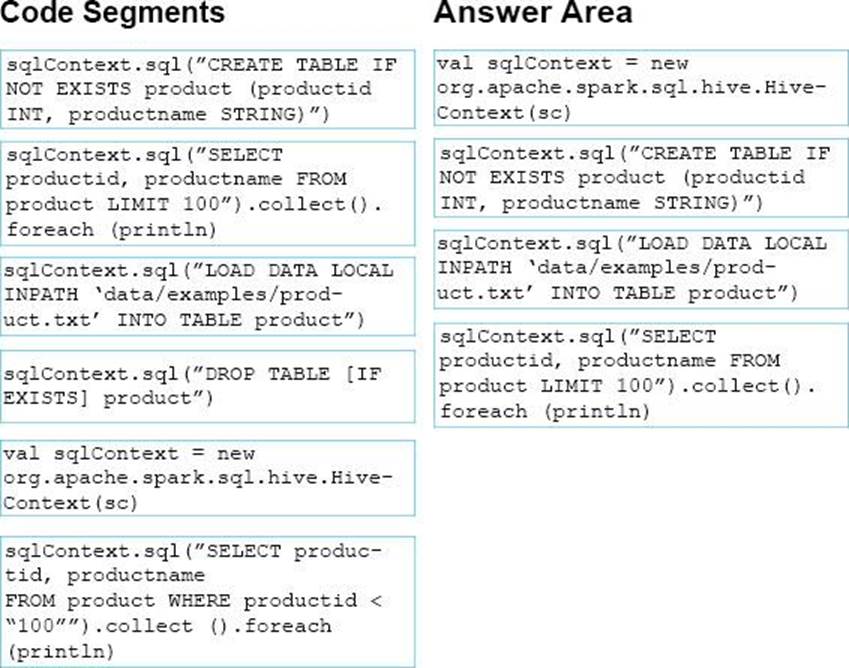
You have a text file named Data/examples/product.txt that contains product information.
You need to create a new Apache Hive table, import the product information to the table, and then read the top 100 rows of the table.
Which four code segments should you use in sequence? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
정답:
Explanation:
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql(“CREATE TABLE IF NOT EXISTS productid INT, productname STRING)” sqlContext.sql("LOAD DATA LOCAL INPATH ‘Data/examples/product.txt’ INTO TABLE product")
sqlContext.sql("SELECT productid, productname FROM product LIMIT 100").collect().foreach (println)
References: https://www.tutorialspoint.com/spark_sql/spark_sql_hive_tables.htm
Question No : 13
You use YARN to manage the resources for a Spark Thrift Server running on a Linux-based
Apache Spark cluster in Azure HDInsight. You discover that the cluster does not fully utilize the resources. You want to increase resource allocation.
You need to increase the number of executors and the allocation of memory to the Spark Thrift Server driver.
Which two parameters should you modify? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
You have an Apache Spark cluster in Azure HDInsight.
You execute the following command.
What is the result of running the command?
정답:
Question No : 15
DRAG DROP
You have an Apache Hive cluster in Azure HDInsight.
You need to tune a Hive query to meet the following requirements:
- Use the Tez engine.
- Process 1,024 rows in a batch.
How should you complete the query? To answer, drag the appropriate values to the correct
targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.