
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
Databricks Certified Data Engineer Associate Exam 온라인 연습
최종 업데이트 시간: 2025년11월09일
당신은 온라인 연습 문제를 통해 Databricks Databricks Certified Data Engineer Associate 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 Databricks Certified Data Engineer Associate 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 87개의 시험 문제와 답을 포함하십시오.

정답:
Explanation:
https://docs.yugabyte.com/preview/integrations/apache-spark/spark-sql/ CREATE TABLE new_employees_table USING JDBC
OPTIONS (
url "<jdbc_url>",
dbtable "<table_name>",
user '<username>',
password '<password>'
) AS
SELECT * FROM employees_table_vw
https://docs.databricks.com/external-data/jdbc.html#language-sql

정답:
Explanation:
https://docs.databricks.com/en/ingestion/copy-into/index.html
The COPY INTO SQL command lets you load data from a file location into a Delta table. This is a re-triable and idempotent operation; files in the source location that have already been loaded are skipped. if there are no new records, the only consistent choice is C no new files were loaded because already loaded files were skipped.
정답:





정답:
Explanation:
https://www.databricks.com/blog/2021/10/20/introducing-sql-user-defined-functions.html
정답:
Explanation:
To write data into a Delta table while avoiding the writing of duplicate records, you can use the MERGE command. The MERGE command in Delta Lake allows you to combine the ability to insert new records and update existing records in a single atomic operation. The MERGE command compares the data being written with the existing data in the Delta table based on specified matching criteria, typically using a primary key or unique identifier. It then performs conditional actions, such as inserting new records or updating existing records, depending on the comparison results. By using the MERGE command, you can handle the prevention of duplicate records in a more controlled and efficient manner. It allows you to synchronize and reconcile data from different sources while avoiding duplication and ensuring data integrity.
정답:
Explanation:
Array functions in Spark SQL are primarily used for working with arrays and complex, nested data structures, such as those often encountered when ingesting JSON files. These functions allow you to manipulate and query nested arrays and structures within your data, making it easier to extract and work with specific elements or values within complex data formats. While some of the other options (such as option A for working with different data types) are features of Spark SQL or SQL in general, array functions specifically excel at handling complex, nested data structures like those found in JSON files.
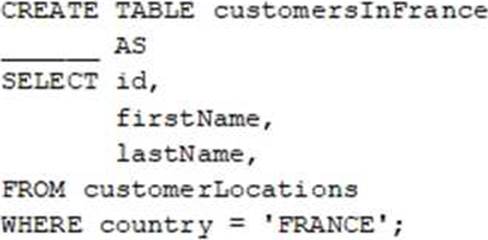
정답:
Explanation:
Ref: https://www.databricks.com/discover/pages/data-quality-management
CREATE TABLE my_table (id INT COMMENT 'Unique Identification Number', name STRING COMMENT 'PII', age INT COMMENT 'PII') TBLPROPERTIES ('contains_pii'=True) COMMENT 'Contains PII';
정답:
Explanation:
To retrieve the location of a database named "customer360" in a database management system like Hive or Databricks, you can use the DESCRIBE DATABASE command followed by the database name.
This command will provide information about the database, including its location.
정답:
Explanation:
https://spark.apache.org/docs/3.2.1/api/python/reference/api/pyspark.sql.SparkSession.table.html
정답:
Explanation:
https://docs.databricks.com/sql/admin/transfer-ownership.html
정답:
Explanation:
An advantage of using Databricks Repos over the built-in Databricks Notebooks versioning is the ability to work with multiple branches. Branching is a fundamental feature of version control systems like Git, which Databricks Repos is built upon. It allows you to create separate branches for different tasks, features, or experiments within your project. This separation helps in parallel development and experimentation without affecting the main branch or the work of other team members. Branching provides a more organized and collaborative development environment, making it easier to merge changes and manage different development efforts. While Databricks Notebooks versioning also allows you to track versions of notebooks, it may not provide the same level of flexibility and collaboration as branching in Databricks Repos.
정답:
Explanation:
One of the key features of a data lakehouse that results in improved data quality over a traditional data lake is its support for ACID (Atomicity, Consistency, Isolation, Durability) transactions. ACID transactions provide data integrity and consistency guarantees, ensuring that operations on the data are reliable and that data is not left in an inconsistent state due to failures or concurrent access. In a traditional data lake, such transactional guarantees are often lacking, making it challenging to maintain data quality, especially in scenarios involving multiple data writes, updates, or complex transformations. A data lakehouse, by offering ACID compliance, helps maintain data quality by providing strong consistency and reliability, which is crucial for data pipelines and analytics.
정답:
Explanation:
For following tasks, work in your Git provider:
Create a pull request.
Resolve merge conflicts.
Merge or delete branches.
Rebase a branch.
https://docs.databricks.com/repos/index.html
정답:
Explanation:
The VACUUM command in Delta Lake is used to clean up and remove unnecessary data files that are no longer needed for time travel or query purposes. When you run VACUUM with certain retention settings, it can delete older data files, which might include versions of data that are older than the specified retention period. If the data engineer is unable to restore the table to a version that is 3 days old because the data files have been deleted, it's likely because the VACUUM command was run on the table, removing the older data files as part of data cleanup.
정답: