
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
Designing and Implementing a Data Science Solution on Azure 온라인 연습
최종 업데이트 시간: 2025년04월10일
당신은 온라인 연습 문제를 통해 Microsoft DP-100 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 DP-100 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 110개의 시험 문제와 답을 포함하십시오.
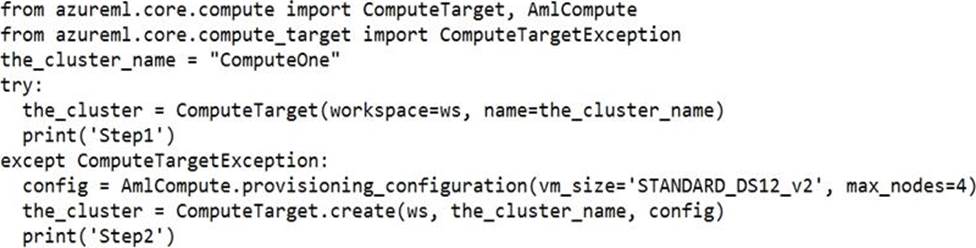
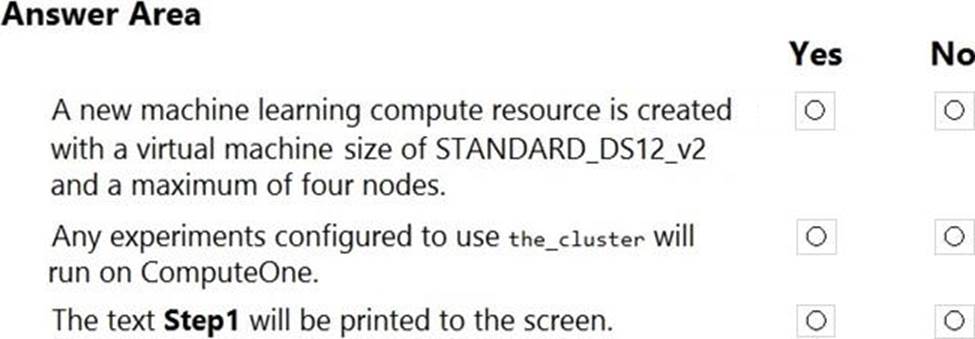
정답: 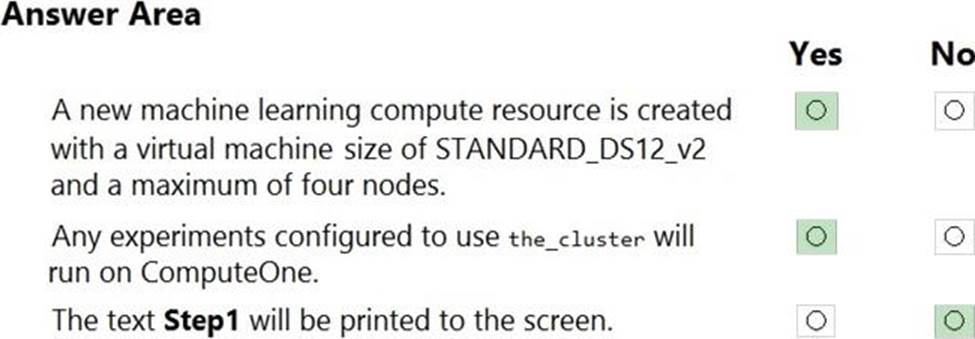
Explanation:
Box 1: Yes
ComputeTargetException class: An exception related to failures when creating, interacting with, or configuring a compute target. This exception is commonly raised for failures attaching a compute target, missing headers, and unsupported configuration values.
Create (workspace, name, provisioning_configuration)
Provision a Compute object by specifying a compute type and related configuration.
This method creates a new compute target rather than attaching an existing one.
Box 2: Yes
Box 3: No
The line before print('Step1') will fail.
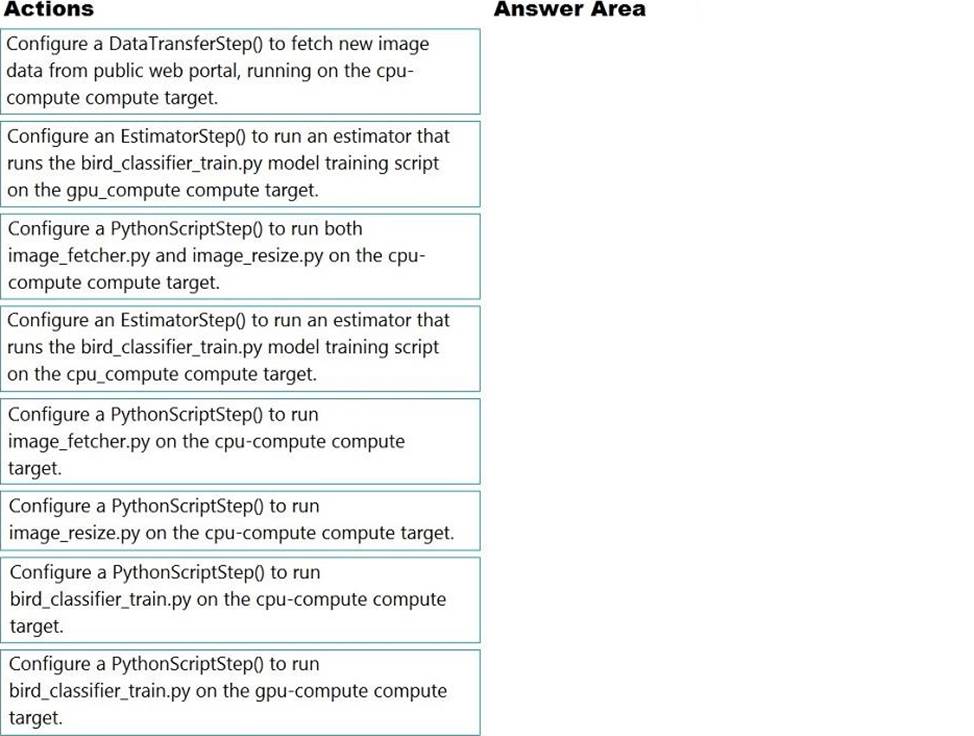
정답: 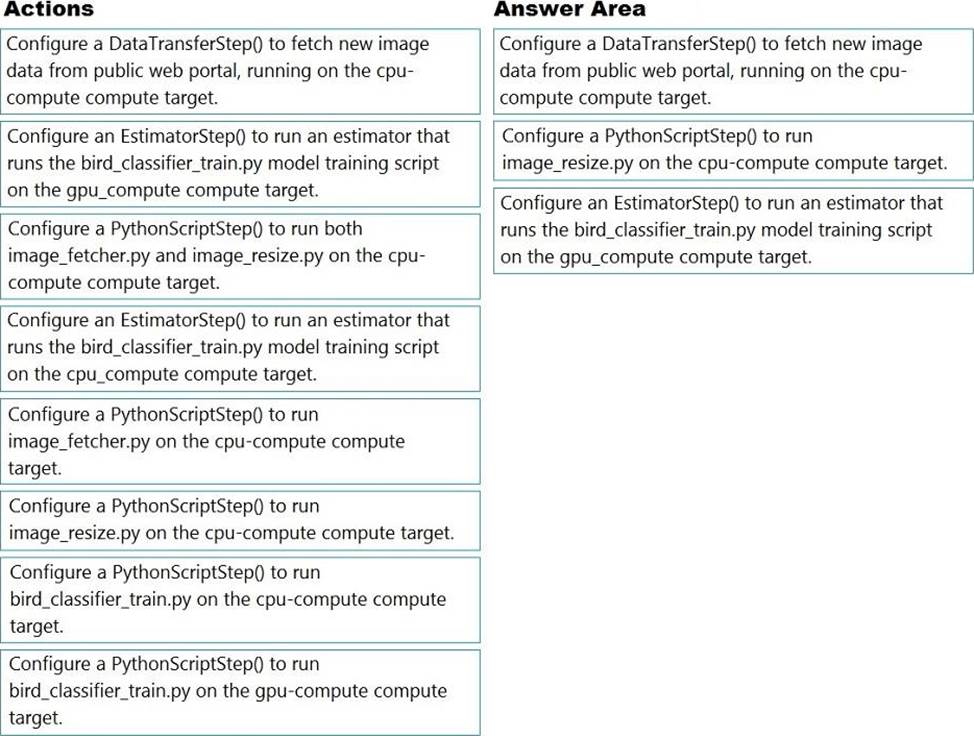
Explanation:
Step 1: Configure a DataTransferStep() to fetch new image data…
Step 2: Configure a PythonScriptStep() to run image_resize.y on the cpu-compute compute target.
Step 3: Configure the EstimatorStep() to run training script on the gpu_compute computer target.
The PyTorch estimator provides a simple way of launching a PyTorch training job on a compute target.


정답: 
Explanation:
Box 1: Yes
Hyperparameters are adjustable parameters you choose to train a model that govern the training process itself. Azure Machine Learning allows you to automate hyperparameter exploration in an efficient manner, saving you significant time and resources. You specify the range of hyperparameter values and a maximum number of training runs. The system then automatically launches multiple simultaneous runs with different parameter configurations and finds the configuration that results in the best performance, measured by the metric you choose. Poorly performing training runs are automatically early terminated, reducing wastage of compute resources. These resources are instead used to explore other hyperparameter configurations.
Box 2: Yes
uniform (low, high) - Returns a value uniformly distributed between low and high
Box 3: No
Bayesian sampling does not currently support any early termination policy.
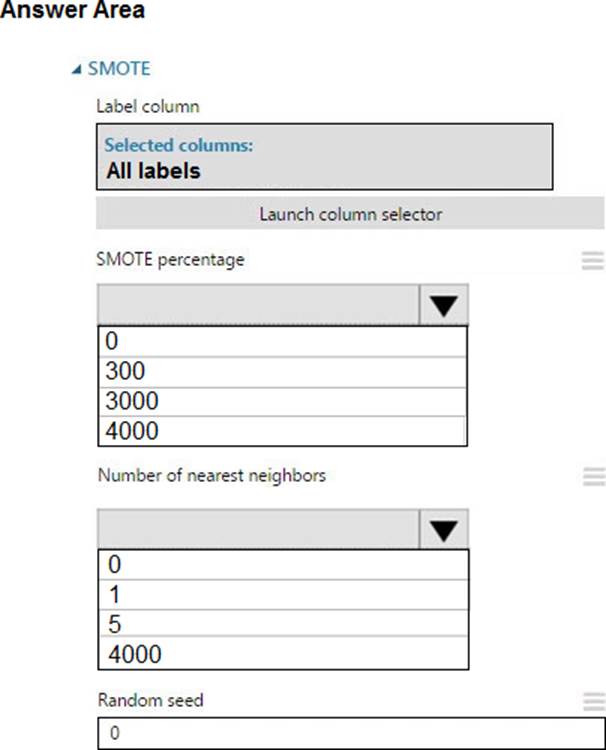
정답: 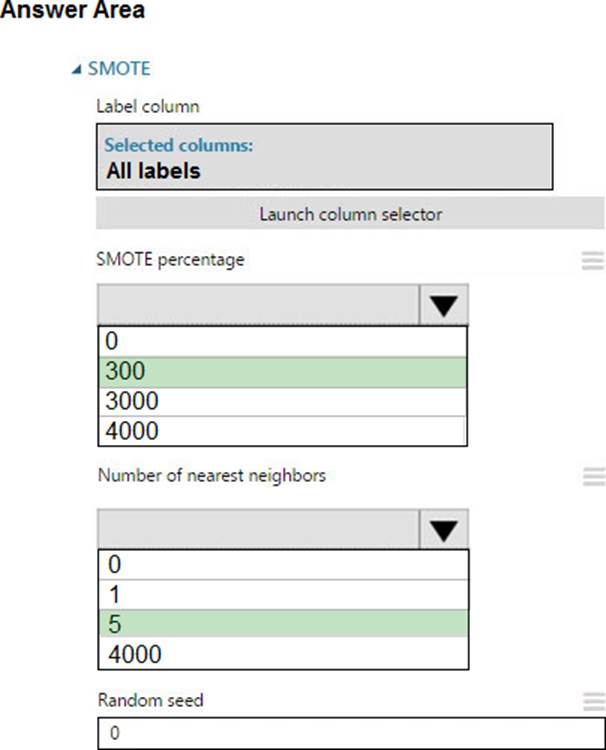
Explanation:
Box 1: 300
You type 300 (%), the module triples the percentage of minority cases (3000) compared to the original dataset (1000).
Box 2: 5
We should use 5 data rows.
Use the Number of nearest neighbors option to determine the size of the feature space that the SMOTE algorithm uses when in building new cases. A nearest neighbor is a row of data (a case) that is very similar to some target case. The distance between any two cases is measured by combining the weighted vectors of all features.
By increasing the number of nearest neighbors, you get features from more cases.
By keeping the number of nearest neighbors low, you use features that are more like those in the original sample.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
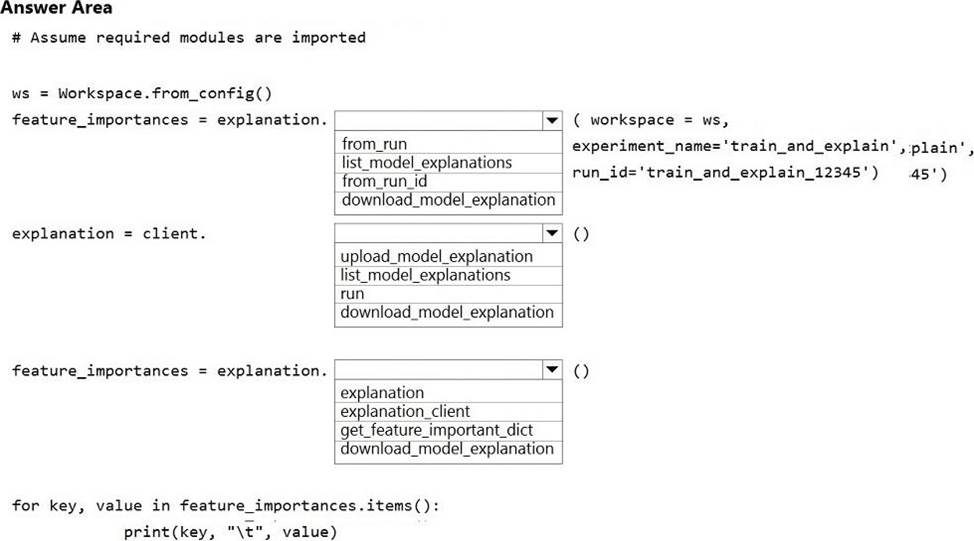
정답: 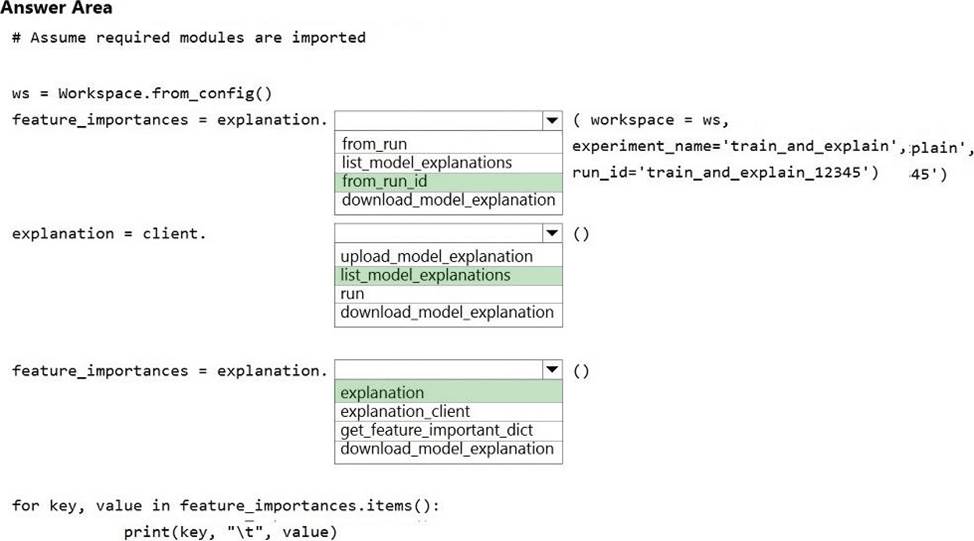
Explanation:
Box 1: from_run_id
from_run_id(workspace, experiment_name, run_id) Create the client with factory method given a run ID.
Returns an instance of the ExplanationClient.
Parameters
✑ Workspace Workspace An object that represents a workspace.
✑ experiment_name str The name of an experiment.
✑ run_id str A GUID that represents a run.
Box 2: list_model_explanations
list_model_explanations returns a dictionary of metadata for all model explanations available.
Returns
A dictionary of explanation metadata such as id, data type, explanation method, model type, and upload time, sorted by upload time
Box 3: explanation
정답:
Explanation:
azureml.core.Model.properties:
Dictionary of key value properties for the Model. These properties cannot be changed after registration, however new key value pairs can be added.
Reference: https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.model.model


정답: 
Explanation:
Box 1: No
max_total_runs (50 here)
The maximum total number of runs to create. This is the upper bound; there may be fewer runs when the sample space is smaller than this value.
Box 2: Yes
Policy EarlyTerminationPolicy
The early termination policy to use. If None - the default, no early termination policy will be used.
Box 3: No
Discrete hyperparameters are specified as a choice among discrete values. choice can be:
one or more comma-separated values
✑ a range object
✑ any arbitrary list object
정답:
Explanation:
Remove entire row: Completely removes any row in the dataset that has one or more missing values. This is useful if the missing value can be considered randomly missing.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
정답:
Explanation:
Use the Entropy MDL binning mode which has a target column.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/group-data-into-bins
정답:
Explanation:
B: Continuous hyperparameters are specified as a distribution over a continuous range of values. Supported distributions include:
✑ uniform(low, high) - Returns a value uniformly distributed between low and high
D: Discrete hyperparameters are specified as a choice among discrete values. choice can be:
✑ one or more comma-separated values
✑ a range object
✑ any arbitrary list object
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-tune-hyperparameters
정답:
Explanation:
SMOTE is used to increase the number of underepresented cases in a dataset used for machine learning. SMOTE is a better way of increasing the number of rare cases than simply duplicating existing cases.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
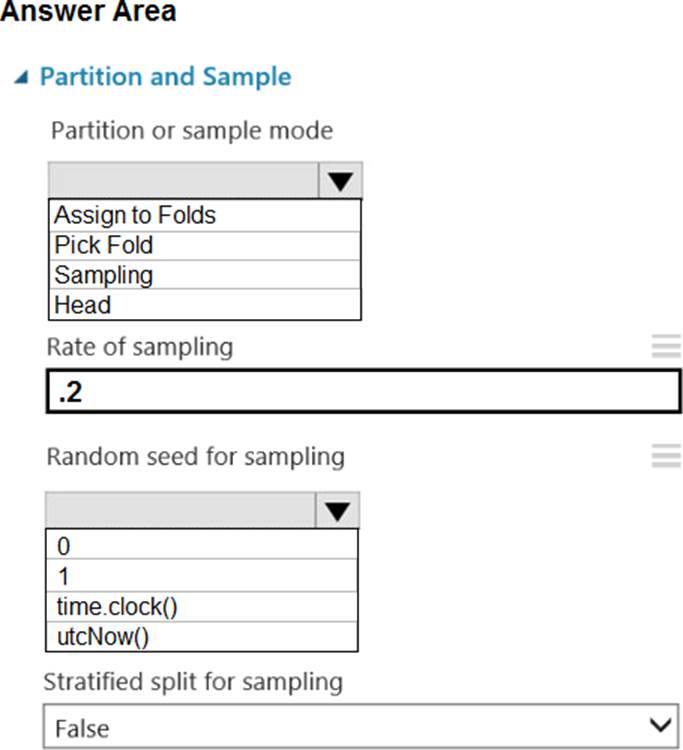
정답: 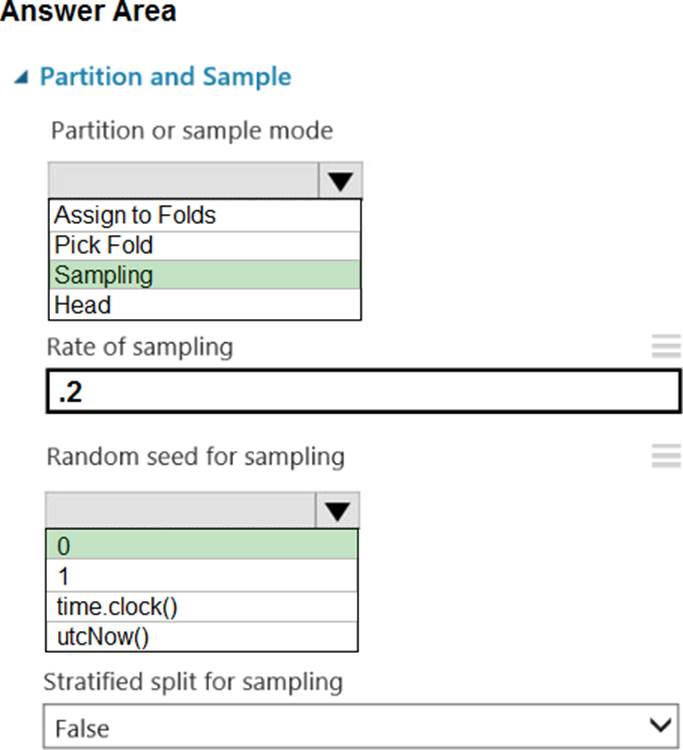
Explanation:
Box 1: Sampling
Create a sample of data
This option supports simple random sampling or stratified random sampling. This is useful if you want to create a smaller representative sample dataset for testing.
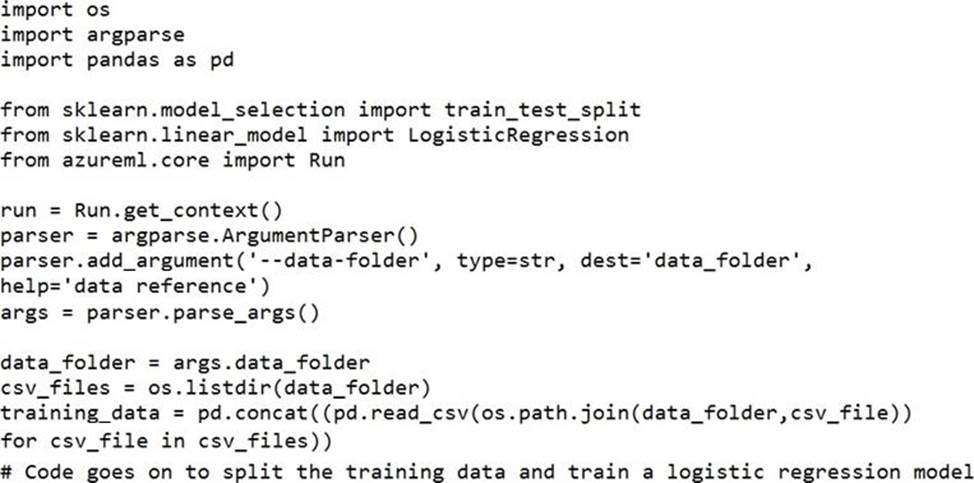
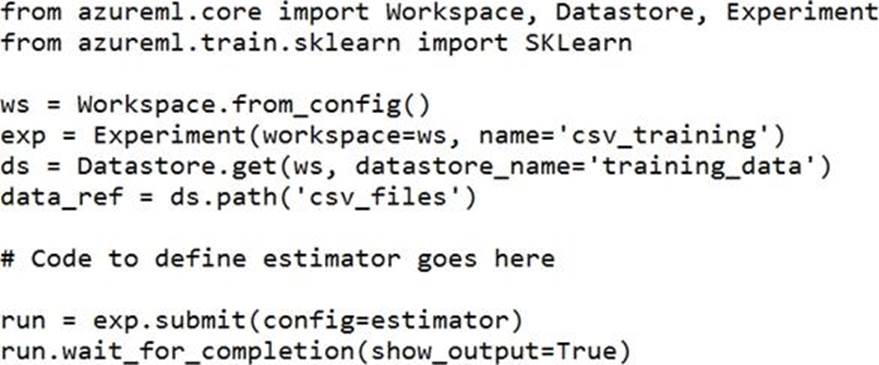

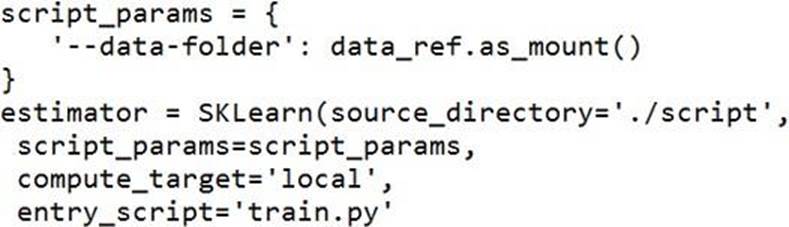



정답:
Explanation:
Besides passing the dataset through the inputs parameter in the estimator, you can also pass the dataset through script_params and get the data path (mounting point) in your training script via arguments. This way, you can keep your training script independent of azureml-sdk. In other words, you will be able use the same training script for local debugging and remote training on any cloud platform.
Example:
from azureml.train.sklearn import SKLearn
script_params = {
# mount the dataset
on the remote compute and pass the mounted path as an argument to the training
script
'--data-folder':
mnist_ds.as_named_input('mnist').as_mount(),
'--regularization':

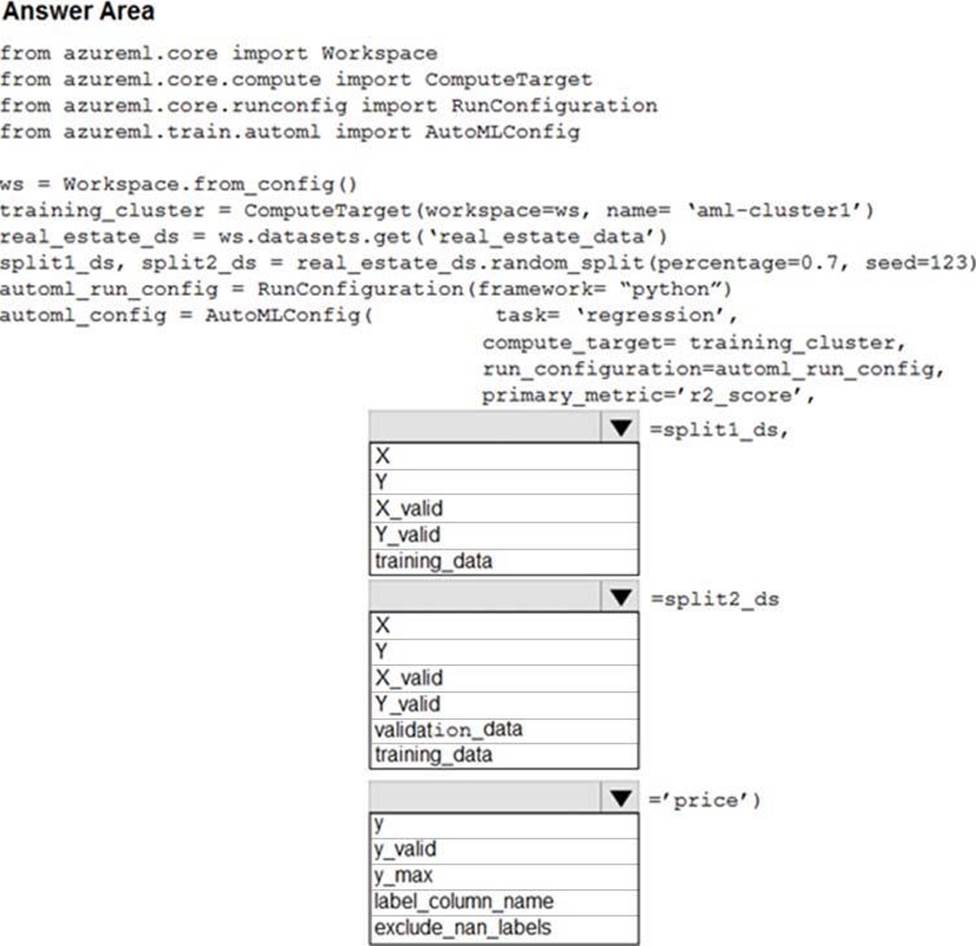
정답: 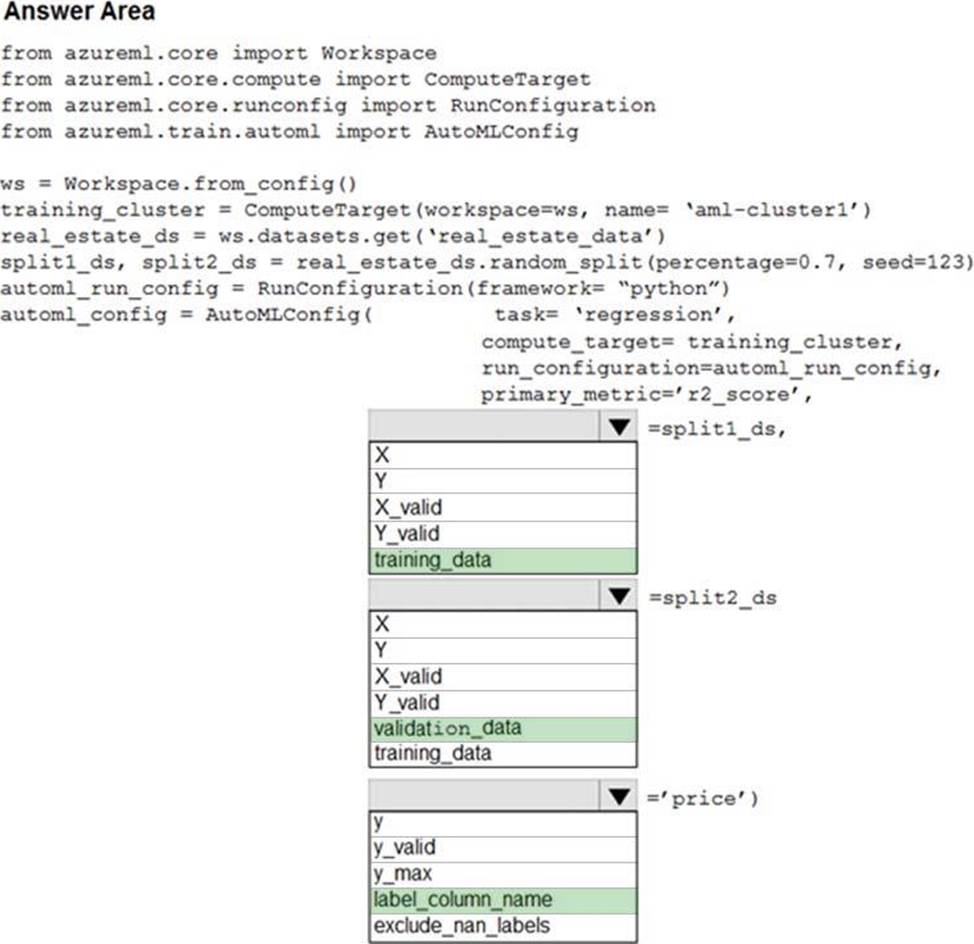
Explanation:
Box 1: training_data
The training data to be used within the experiment. It should contain both training features and a label column (optionally a sample weights column). If training_data is specified, then the label_column_name parameter must also be specified.
Box 2: validation_data
Provide validation data: In this case, you can either start with a single data file and split it into training and validation sets or you can provide a separate data file for the validation set. Either way, the validation_data parameter in your AutoMLConfig object assigns which data to use as your validation set.
Example, the following code example explicitly defines which portion of the provided data in dataset to use for training and validation.
dataset = Dataset.Tabular.from_delimited_files(data)
training_data, validation_data = dataset.random_split(percentage=0.8, seed=1)
automl_config = AutoMLConfig(compute_target = aml_remote_compute, task = 'classification',
primary_metric = 'AUC_weighted',
training_data = training_data,
validation_data = validation_data,
label_column_name = 'Class'
)
Box 3: label_column_name
label_column_name:
The name of the label column. If the input data is from a pandas.DataFrame which doesn't have column names, column indices can be used instead, expressed as integers.
This parameter is applicable to training_data and validation_data parameters.
정답:
Explanation:
Replace using MICE: For each missing value, this option assigns a new value, which is calculated by using a method described in the statistical literature as "Multivariate Imputation using Chained Equations" or "Multiple Imputation by Chained Equations". With a multiple imputation method, each variable with missing data is modeled conditionally using the other variables in the data before filling in the missing values.
Note: Multivariate imputation by chained equations (MICE), sometimes called “fully conditional specification” or “sequential regression multiple imputation” has emerged in the statistical literature as one principled method of addressing missing data. Creating multiple imputations, as opposed to single imputations, accounts for the statistical uncertainty in the imputations. In addition, the chained equations approach is very flexible and can handle variables of varying types (e.g., continuous or binary) as well as complexities such as bounds or survey skip patterns.
References:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3074241/
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data