당신은 온라인 연습 문제를 통해 Microsoft DP-200 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 DP-200 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 192개의 시험 문제와 답을 포함하십시오.
/ 4
Question No : 1
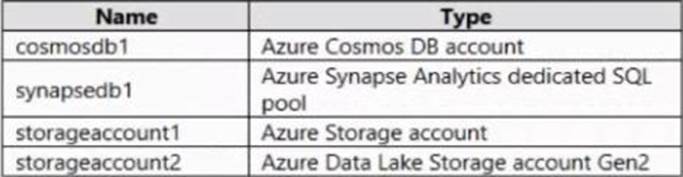
You have an Azure subscription that contains the resources shown in the following table.
All the resources have the default encryption settings.
정답:
Question No : 2
You have an Azure Storage account.
You need to configure the storage account to send an email when an administrative action is performed on the account.
What should you do?
정답: Explanation:
To determine if there is an activity log alert created for "Create/Update Storage Account" events in your Microsoft Azure cloud account, perform the following actions:
✑ Sign in to Azure Management Console.
✑ Navigate to Azure Monitor blade
✑ In the navigation panel, select Alerts to access all the alerts available in your cloud account.
✑ On the Alerts page, click on the Manage alert rules button from the dashboard top menu to access the alert rules management page.
✑ On the Rules page, select the subscription that you want to examine from the Subscription filter box and the Enabled option from the Status dropdown list, to return all the active alert rules created in the selected account subscription.
✑ Click on the name of the alert rule that you want to examine.
✑ On the selected alert rule configuration page, check the condition phrase available in the Condition section. If the phrase is different than Whenever the Activity Log
has an event with Category='Administrative', Signal name='Create/Update Storage Account (Microsoft.Storage/storageAccounts)', the selected alert rule is not designed to fire whenever "Create Storage Account" or "Update Storage Account" events are triggered.
Reference: https://www.cloudconformity.com/knowledge-base/azure/ActivityLog/create-storage-account-alert.html
Question No : 3
CORRECT TEXT
Use the following login credentials as needed:
Azure Username: xxxxx
Azure Password: xxxxx
The following information is for technical support purposes only:
Lab Instance: 10277521
You need to generate an email notification to [email protected] if the available storage in an Azure Cosmos DB database named cosmos10277521 is less than 100,000,000 bytes.
To complete this task, sign in to the Azure portal.
정답:
Question No : 4
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a solution that will use Azure Stream Analytics. The solution will accept an Azure Blob storage file named Customers. The file will contain both in-store and online customer details. The online customers will provide a mailing address.
You have a file in Blob storage named LocationIncomes that contains based on location.
The file rarely changes.
You need to use an address to look up a median income based on location. You must
output the data to Azure SQL Database for immediate use and to Azure Data Lake Storage Gen2 for long-term retention.
Solution: You implement a Stream Analytics job that has one streaming input, one reference input, one query, and two outputs.
Does this meet the goal?
정답: Explanation:
We need one reference data input for LocationIncomes, which rarely changes.
We need two queries, on for in-store customers, and one for online customers.
For each query two outputs is needed.
Note: Stream Analytics also supports input known as reference data. Reference data is either completely static or changes slowly.
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-add-inputs#stream-and-reference-inputs
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-define-outputs
Question No : 5
DRAG DROP
You manage security for a database that supports a line of business application.
Private and personal data stored in the database must be protected and encrypted.
You need to configure the database to use Transparent Data Encryption (TDE).
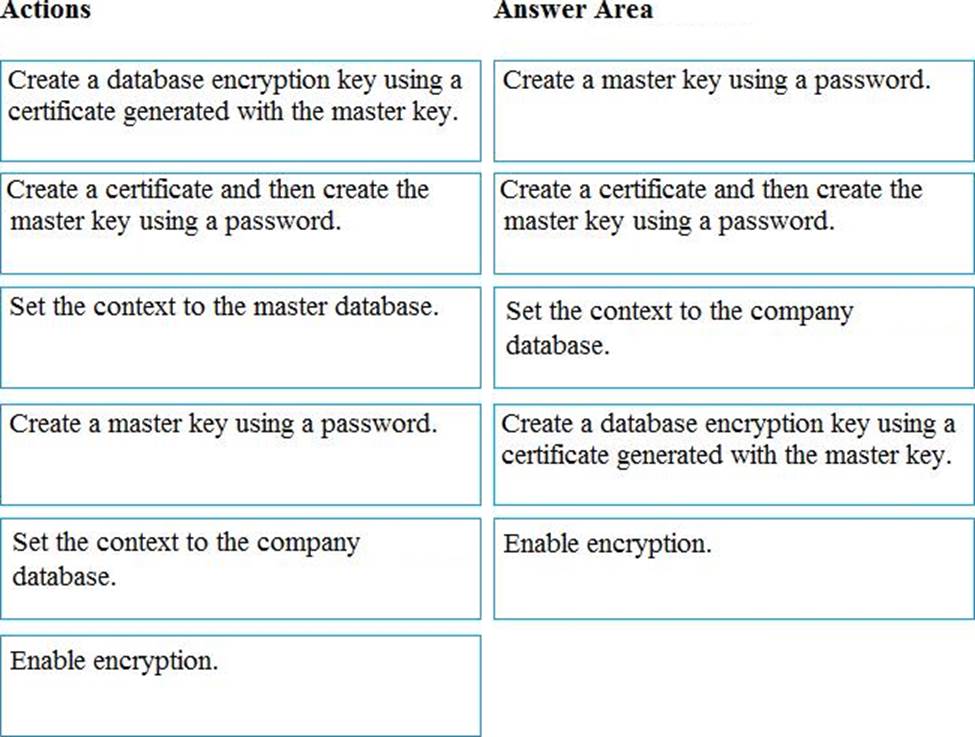
Which five actions should you perform in sequence? To answer, select the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
정답:
Explanation:
Step 1: Create a master key
Step 2: Create or obtain a certificate protected by the master key
Step 3: Set the context to the company database
Step 4: Create a database encryption key and protect it by the certificate
Step 5: Set the database to use encryption
Example code:
USE master;
GO
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<UseStrongPasswordHere>';
go
CREATE CERTIFICATE MyServerCert WITH SUBJECT = 'My DEK Certificate';
go
USE AdventureWorks2012;
GO
CREATE DATABASE ENCRYPTION KEY
WITH ALGORITHM = AES_128
ENCRYPTION BY SERVER CERTIFICATE MyServerCert;
GO
ALTER DATABASE AdventureWorks2012
SET ENCRYPTION ON;
GO
Reference: https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/transparent-data-encryption
Question No : 6
HOTSPOT
You have an Azure SQL database that contains a table named Employee. Employee contains sensitive data in a decimal (10,2) column named Salary.
You need to ensure that nonprivileged users can view the table data, but Salary must display a number from 0 to 100.
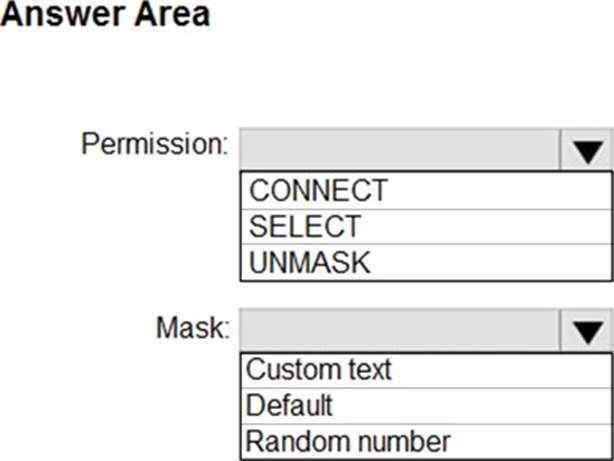
What should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
정답:
Explanation:
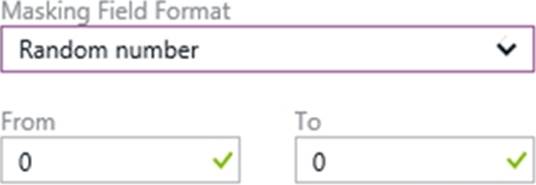
Box 1: SELECT
Users with SELECT permission on a table can view the table data. Columns that are defined as masked, will display the masked data.
Incorrect:
Grant the UNMASK permission to a user to enable them to retrieve unmasked data from the columns for which masking is defined.
The CONTROL permission on the database includes both the ALTER ANY MASK and UNMASK permission.
Box 2: Random number
Random number: Masking method, which generates a random number according to the selected boundaries and actual data types. If the designated boundaries are equal, then the masking function is a constant number.
Question No : 7
CORRECT TEXT
Use the following login credentials as needed:
Azure Username: xxxxx
Azure Password: xxxxx
The following information is for technical support purposes only:
Lab Instance: 10543936
You plan to enable Azure Multi-Factor Authentication (MFA).
You need to ensure that [email protected] can manage any databases hosted on an Azure SQL server named SQL10543936 by signing in using his Azure Active Directory (Azure AD) user account.
To complete this task, sign in to the Azure portal.
정답: Provision an Azure Active Directory administrator for your managed instance
Each Azure SQL server (which hosts a SQL Database or SQL Data Warehouse) starts with a single server administrator account that is the administrator of the entire Azure SQL server. A second SQL Server administrator must be created, that is an Azure AD account. This principal is created as a contained database user in the master database.
Question No : 8
A company is designing a hybrid solution to synchronize data and on-premises Microsoft SQL Server database to Azure SQL Database.
You must perform an assessment of databases to determine whether data will move without compatibility issues.
You need to perform the assessment.
Which tool should you use?
정답: Explanation:
The Data Migration Assistant (DMA) helps you upgrade to a modern data platform by detecting compatibility issues that can impact database functionality in your new version of SQL Server or Azure SQL Database. DMA recommends performance and reliability improvements for your target environment and allows you to move your schema, data, and uncontained objects from your source server to your target server.
References: https://docs.microsoft.com/en-us/sql/dma/dma-overview
Question No : 9
HOTSPOT
A company runs Microsoft Dynamics CRM with Microsoft SQL Server on-premises. SQL Server Integration Services (SSIS) packages extract data from Dynamics CRM APIs, and load the data into a SQL Server data warehouse.
The datacenter is running out of capacity. Because of the network configuration, you must extract on premises data to the cloud over https. You cannot open any additional ports. The solution must implement the least amount of effort.
You need to create the pipeline system.
Which component should you use? To answer, select the appropriate technology in the dialog box in the answer area. NOTE: Each correct selection is worth one point.
정답:
Explanation:
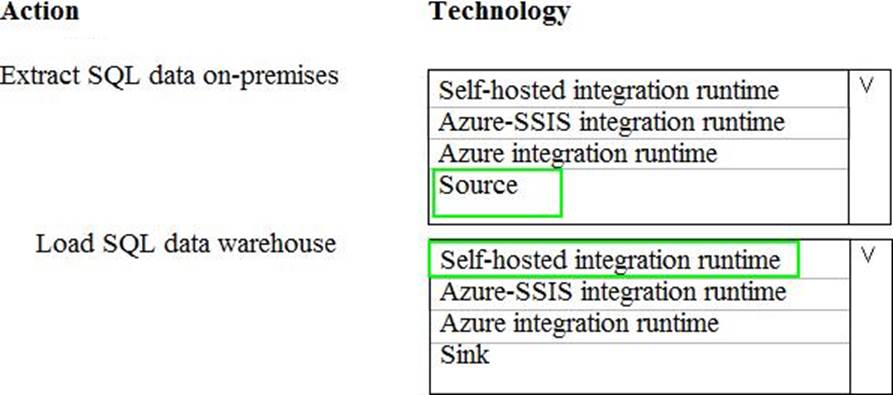
Box 1: Source
For Copy activity, it requires source and sink linked services to define the direction of data flow.
Copying between a cloud data source and a data source in private network: if either source or sink linked service points to a self-hosted IR, the copy activity is executed on that self-hosted Integration Runtime.
Box 2: Self-hosted integration runtime
A self-hosted integration runtime can run copy activities between a cloud data store and a data store in a private network, and it can dispatch transform activities against compute resources in an on-premises network or an Azure virtual network. The installation of a self-hosted integration runtime needs on an on-premises machine or a virtual machine (VM) inside a private network.
References: https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime
Question No : 10
You are designing an enterprise data warehouse in Azure Synapse Analytics. You plan to load millions of rows of data into the data warehouse each day.
You must ensure that staging tables are optimized for data loading.
You need to design the staging tables.
What type of tables should you recommend?
정답:
Question No : 11
DRAG DROP
You develop data engineering solutions for a company.
You need to deploy a Microsoft Azure Stream Analytics job for an IoT solution.
The solution must:
• Minimize latency.
• Minimize bandwidth usage between the job and IoT device.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
정답:
Question No : 12
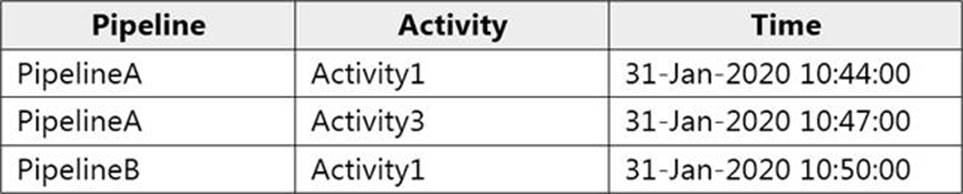
HOTSPOT
You have an Azure data factory that has two pipelines named PipelineA and PipelineB.
PipelineA has four activities as shown in the following exhibit.
PipelineB has two activities as shown in the following exhibit.
You create an alert for the data factory that uses Failed pipeline runs metrics for both pipelines and all failure types.
The metric has the following settings:
✑ Operator: Greater than
✑ Aggregation type: Total
✑ Threshold value: 2
✑ Aggregation granularity (Period): 5 minutes
✑ Frequency of evaluation: Every 5 minutes
Data Factory monitoring records the failures shown in the following table.
For each of the following statements, select yes if the statement is true. Otherwise, select no. NOTE: Each correct answer selection is worth one point.
정답:
Explanation:
Box 1: No
Only one failure at this point.
Box 2: No
Only two failures within 5 minutes.
Box 3: Yes
More than two (three) failures in 5 minutes
Question No : 13
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to create an Azure Databricks workspace that has a tiered structure.
The workspace will contain the following three workloads:
✑ A workload for data engineers who will use Python and SQL
✑ A workload for jobs that will run notebooks that use Python, Spark, Scala, and SQL
✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R
The enterprise architecture team at your company identifies the following standards for Databricks environments:
✑ The data engineers must share a cluster.
✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster.
✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists.
You need to create the Databrick clusters for the workloads.
Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a Standard cluster for the jobs.
Does this meet the goal?
정답: Explanation:
We need a High Concurrency cluster for the data engineers and the jobs.
Note:
Standard clusters are recommended for a single user. Standard can run workloads developed in any language: Python, R, Scala, and SQL.
A high concurrency cluster is a managed cloud resource. The key benefits of high concurrency clusters are that they provide Apache Spark-native fine-grained sharing for maximum resource utilization and minimum query latencies.
References: https://docs.azuredatabricks.net/clusters/configure.html
Question No : 14
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure subscription that contains an Azure Storage account.
You plan to implement changes to a data storage solution to meet regulatory and compliance standards.
Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days.
Solution: You schedule an Azure Data Factory pipeline.
Does this meet the goal?
Your company uses several Azure HDInsight clusters.
The data engineering team reports several errors with some application using these clusters.
You need to recommend a solution to review the health of the clusters.
What should you include in you recommendation?
정답: Explanation:
Azure Monitor logs integration. Azure Monitor logs enables data generated by multiple resources such as HDInsight clusters, to be collected and aggregated in one place to
achieve a unified monitoring experience.
As a prerequisite, you will need a Log Analytics Workspace to store the collected data. If you have not already created one, you can follow the instructions for creating a Log Analytics Workspace.
You can then easily configure an HDInsight cluster to send many workload-specific metrics to Log Analytics.
References: https://azure.microsoft.com/sv-se/blog/monitoring-on-azure-hdinsight-part-2-cluster-health-and-availability/