
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
Administering Relational Databases on Microsoft Azure 온라인 연습
최종 업데이트 시간: 2025년03월22일
당신은 온라인 연습 문제를 통해 Microsoft DP-300 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 DP-300 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 56개의 시험 문제와 답을 포함하십시오.
정답:
Explanation:
To send a notification in response to an alert, you must first configure SQL Server Agent to send mail.
Using SQL Server Management Studio; to configure SQL Server Agent to use Database Mail:
✑ In Object Explorer, expand a SQL Server instance.
✑ Right-click SQL Server Agent, and then click Properties.
✑ Click Alert System.
✑ Select Enable Mail Profile.
✑ In the Mail system list, select Database Mail.
✑ In the Mail profile list, select a mail profile for Database Mail.
✑ Restart SQL Server Agent.
Note: Prerequisites include:
✑ Enable Database Mail.
✑ Create a Database Mail account for the SQL Server Agent service account to use.
✑ Create a Database Mail profile for the SQL Server Agent service account to use
and add the user to the DatabaseMailUserRole in the msdb database.
✑ Set the profile as the default profile for the msdb database.
Reference: https://docs.microsoft.com/en-us/sql/relational-databases/database-mail/configure-sql-server-agent-mail-to-use-database-mail
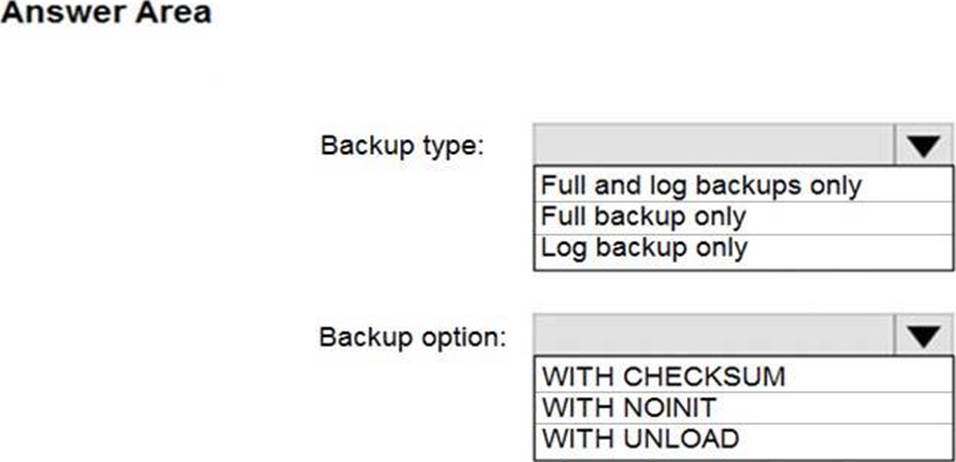
정답: 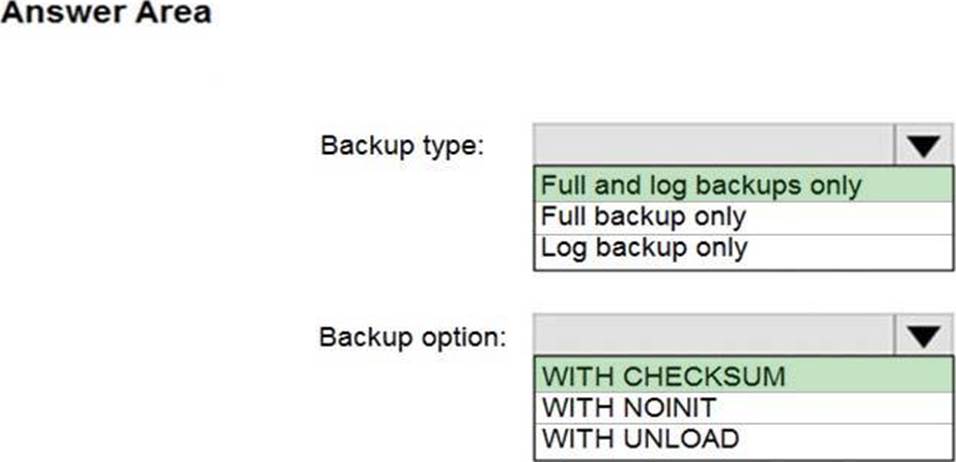
Explanation:
Box 1: Full and log backups only
Make sure to take every backup on a separate backup media (backup files). Azure Database Migration Service doesn't support backups that are appended to a single backup file. Take full backup and log backups to separate backup files.
Box 2: WITH CHECKSUM
Azure Database Migration Service uses the backup and restore method to migrate your on-premises databases to SQL Managed Instance. Azure Database Migration Service only supports backups created using checksum.
정답:
Explanation:
Azure Data Factory annotations help you easily filter different Azure Data Factory objects based on a tag. You can define tags so you can see their performance or find errors faster.
Reference: https://www.techtalkcorner.com/monitor-azure-data-factory-annotations/
정답:
Explanation:
Reference: https://docs.microsoft.com/en-us/sql/t-sql/statements/set-showplan-all-transact-sql?view=sql-server-ver15

정답: 
Explanation:
Graphical user interface, text, chat or text message
Description automatically generated
P1: Set the Partition option to Dynamic Range.
The SQL Server connector in copy activity provides built-in data partitioning to copy data in parallel.
P2: Set the Copy method to PolyBase
Polybase is the most efficient way to move data into Azure Synapse Analytics. Use the staging blob feature to achieve high load speeds from all types of data stores, including Azure Blob storage and Data Lake Store. (Polybase supports Azure Blob storage and Azure Data Lake Store by default.)
정답:
Explanation:
CE: Estimate the vCores needed for the pool as follows:
For vCore-based purchasing model: MAX(<Total number of DBs X average vCore utilization per DB>, <Number of concurrently peaking DBs X Peak vCore utilization per DB)
A: Estimate the storage space needed for the pool by adding the number of bytes needed for all the databases in the pool.
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/elastic-pool-overview
정답:
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/configure-max-degree-of-parallelism
정답:
Explanation:
Serverless SQL pool can automatically synchronize metadata from Apache Spark. A serverless SQL pool database will be created for each database existing in serverless Apache Spark pools.
For each Spark external table based on Parquet and located in Azure Storage, an external table is created in a serverless SQL pool database. As such, you can shut down your Spark pools and still query Spark external tables from serverless SQL pool.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-storage-files-spark-tables
정답:
Explanation:
Azure SQL Database single database supports Data Sync.
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/features-comparison
정답:
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/resource-limits-vcore-single-databases#business-critical---provisioned-compute---gen4
정답:
Explanation:
Reference: You can override the default language by specifying the language magic command %<language> at the beginning of a cell. The supported magic commands are: %python, %r, %scala, and %sql.
Reference: https://docs.microsoft.com/en-us/azure/databricks/notebooks/notebooks-use
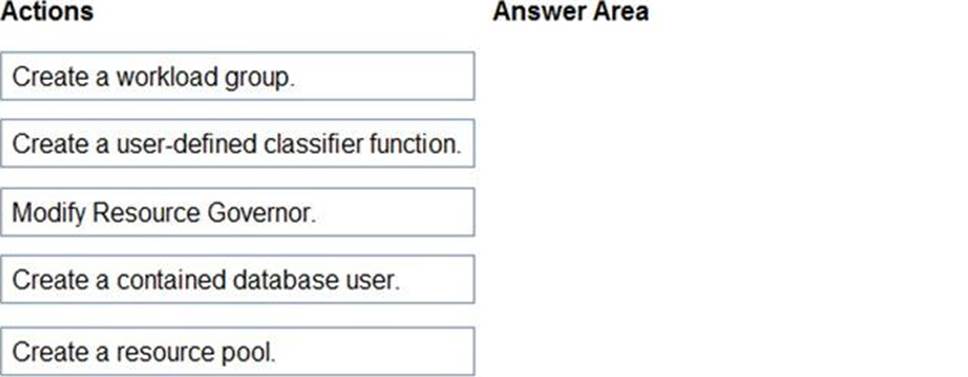
정답: 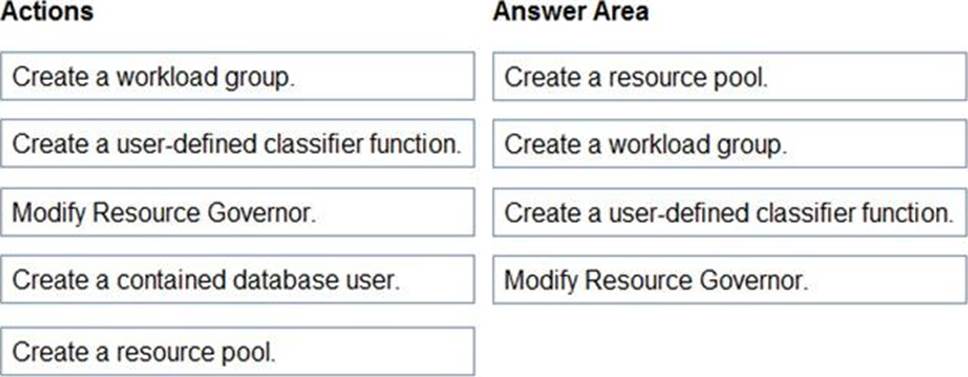
Explanation:
Text, table
Description automatically generated
정답:
Explanation:
A customer-managed key can only be configured on an empty data Factory. The data factory can't contain any resources such as linked services, pipelines and data flows. It is recommended to enable customer-managed key right after factory creation.
Note: Azure Data Factory encrypts data at rest, including entity definitions and any data cached while runs are in progress. By default, data is encrypted with a randomly generated Microsoft-managed key that is uniquely assigned to your data factory.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/enable-customer-managed-key
정답:
Explanation:
Instead deploy an Azure SQL database that uses the Business Critical service tier and Availability Zones.
Note: Premium and Business Critical service tiers leverage the Premium availability model, which integrates compute resources (sqlservr.exe process) and storage (locally attached SSD) on a single node. High availability is achieved by replicating both compute and storage to additional nodes creating a three to four-node cluster.
By default, the cluster of nodes for the premium availability model is created in the same datacenter. With the introduction of Azure Availability Zones, SQL Database can place different replicas of the Business Critical database to different availability zones in the same region. To eliminate a single point of failure, the control ring is also duplicated across multiple zones as three gateway rings (GW).
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/high-availability-sla
정답:
Explanation:
Event-driven architecture (EDA) is a common data integration pattern that involves production, detection, consumption, and reaction to events. Data integration scenarios often require Data Factory customers to trigger pipelines based on events happening in storage account, such as the arrival or deletion of a file in Azure Blob Storage account. Data Factory natively integrates with Azure Event Grid, which lets you trigger pipelines on such events.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/how-to-create-event-trigger