
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
Pure Storage FlashArray Architect Associate 온라인 연습
최종 업데이트 시간: 2025년03월23일
당신은 온라인 연습 문제를 통해 Pure Storage FAAA_004 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 FAAA_004 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 60개의 시험 문제와 답을 포함하십시오.
정답:
Explanation:
The return window as defined by the Love Your Storage Guarantee is 30 days.
Why This Matters:
Love Your Storage Guarantee:
This guarantee allows customers to return or exchange hardware components (e.g., controllers) within a specified return window if they do not meet their needs.
The 30-day return window ensures customers have sufficient time to evaluate the hardware and make adjustments as needed.
Why Not the Other Options?
A. 15 days:
A 15-day return window would be too short for most customers to fully evaluate their hardware and make informed decisions.
C. 60 days:
While 60 days is longer, it exceeds the standard return window defined by Pure Storage for the Love Your Storage Guarantee.
D. 90 days:
A 90-day return window is significantly longer than the standard 30-day period and is not aligned with Pure Storage's policies.
Key Points:
30-Day Return Window: Provides customers with ample time to evaluate hardware components.
Customer-Centric Approach: Reflects Pure Storage's commitment to ensuring customer satisfaction.
Policy Compliance: Ensures alignment with Pure Storage's official return policies.
Reference: Pure Storage Evergreen//Forever Documentation: "Love Your Storage Guarantee Terms and Conditions"
Pure Storage Knowledge Base: "Understanding the Love Your Storage Return Policy"
정답:
Explanation:
The offering that discounts controller upgrades with a purchase of qualifying storage capacity is Love Your Storage.
Why This Matters:
Love Your Storage:
This program is part of Pure Storage's Evergreen//Forever subscription model. It allows customers to upgrade their controllers at a discounted rate when they purchase additional qualifying storage capacity.
The goal is to ensure that customers can modernize their infrastructure without incurring excessive costs, aligning with Pure Storage's commitment to providing flexible and future-proof solutions.
Why Not the Other Options?
B. Right-Size Guarantee:
The Right-Size Guarantee allows customers to trade in existing shelves for higher-capacity ones while only paying for the incremental capacity increase. It does not involve discounts on controller upgrades.
C. Capacity Consolidation:
Capacity Consolidation refers to the ability to consolidate workloads onto fewer arrays or shelves but does not include discounts on controller upgrades.
D. Ever Agile:
Ever Agile is a subscription model that provides flexibility in scaling storage and compute resources but does not specifically discount controller upgrades tied to storage purchases.
Key Points:
Love Your Storage: Discounts controller upgrades when purchasing qualifying storage capacity. Evergreen Benefits: Ensures customers can modernize their infrastructure cost-effectively. Future-Proofing: Aligns with Pure Storage's commitment to delivering long-term value.
Reference: Pure Storage Evergreen//Forever Documentation: "Understanding Love Your Storage"
Pure Storage Whitepaper: "Maximizing Value with Evergreen Subscriptions"
Pure Storage Knowledge Base: "How Love Your Storage Works"
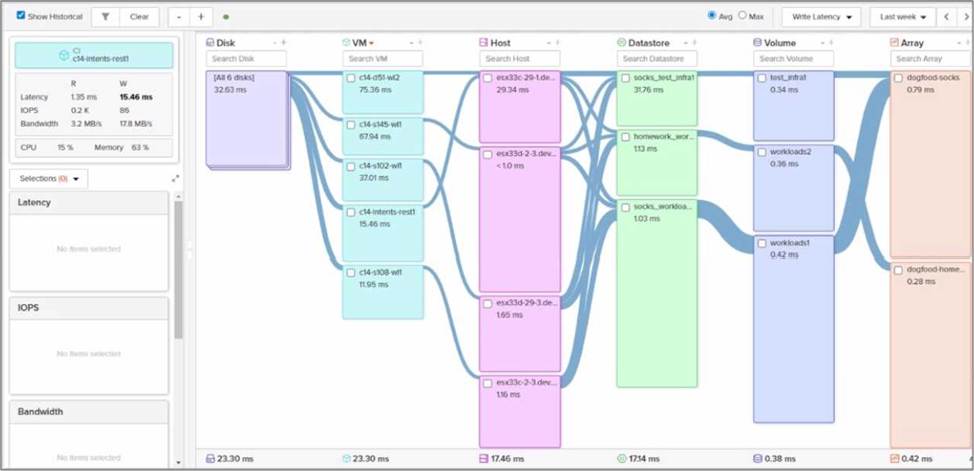
정답:
Explanation:
Write Latency:
Write latency refers to the time it takes for a write operation to complete on the storage array. Lower write latency indicates better performance and faster response times for write-intensive workloads.
In Pure Storage arrays, write latency is typically measured in milliseconds (ms) and can be monitored using tools like Pure1 or Purity//FA performance metrics.
VM-to-Host Mapping:
Each VM runs on an ESXi host, and the write latency of the VM is influenced by the storage performance characteristics of the host it resides on.
To identify the VM with the lowest write latency, we must compare the write latency values for each VM listed in the exhibit.
정답:
Explanation:
The customer wants to achieve the lowest RPO (Recovery Point Objective) possible for their data when replicating between a FlashArray//X70R3 in production and a FlashArray//C60R3 at a secondary site. The best feature to meet this requirement is ActiveDR.
Why This Matters:
ActiveDR:
ActiveDR is an asynchronous replication solution designed for disaster recovery scenarios. It provides low RPOs, typically in the range of seconds to minutes, depending on network conditions and workload characteristics.
While it is asynchronous, ActiveDR achieves much lower RPOs compared to traditional async replication methods like snapshot replication.
It also supports fast failover and failback, ensuring minimal downtime during a disaster recovery event.
Why Not the Other Options?
A. ActiveCluster:
ActiveCluster provides synchronous replication with zero RPO and near-zero RTO. However, it requires both sites to be within a low-latency range (typically <10 ms). Since the customer has not specified that the secondary site is within synchronous distance, ActiveCluster is not feasible in this scenario.
C. Async Replication:
Traditional asynchronous replication (e.g., snapshot replication) typically results in higher RPOs compared to ActiveDR. It does not provide the same level of optimization for low RPOs as ActiveDR.
Key Points:
ActiveDR: Provides the lowest RPO possible for asynchronous replication, making it ideal for geographically distant secondary sites.
Network Latency: ActiveDR is designed to work efficiently over longer distances and higher latencies compared to synchronous solutions like ActiveCluster.
Disaster Recovery: Ensures protection against site failures with minimal data loss and downtime.
Reference: Pure Storage FlashArray Documentation: "ActiveDR for Disaster Recovery"
Pure Storage Whitepaper: "Meeting RPO and RTO Requirements with FlashArray"
Pure Storage Knowledge Base: "Choosing the Right Replication Solution for High Latency"
정답:
Explanation:
The System Administrator requires an offsite backup solution that is cost-effective, stores data in a different location from the current FlashArray, and does not prioritize restore times. The best solution to recommend is CloudSnap to a public cloud provider.
Why This Matters:
CloudSnap:
CloudSnap is a feature that offloads snapshots to cloud storage providers like AWS S3 or Azure Blob.
It is highly cost-effective because customers only pay for the cloud storage they use, and it eliminates the need for additional on-premises hardware.
Since restore times are not a concern, CloudSnap's slower restore process compared to on-premises solutions is acceptable.
Why Not the Other Options?
A. ActiveCluster to a FlashArray//C60:
ActiveCluster provides synchronous replication for high availability but does not meet the requirement for an offsite backup solution. Additionally, it is more expensive than CloudSnap.
B. ActiveDR to a FlashArray//C60:
ActiveDR provides asynchronous replication for disaster recovery but requires additional hardware (FlashArray//C60), which increases costs. It is less cost-effective than CloudSnap for backup purposes.
Key Points:
Cost Efficiency: CloudSnap leverages cloud storage, minimizing upfront and ongoing costs. Offsite Storage: Ensures backups are stored in a different location from the primary FlashArray. Restore Times: CloudSnap's slower restore process is acceptable given the customer's requirements.
Reference: Pure Storage FlashArray Documentation: "CloudSnap for Offsite Backups"
Pure Storage Whitepaper: "Cost-Effective Backup Strategies with FlashArray"
Pure Storage Knowledge Base: "Choosing the Right Backup Solution for Your Workload"
정답:
Explanation:
The customer requires a storage solution that supports a stretched cluster for high availability and also maintains a third copy of their data in a remote geographic location. The best replication method to recommend is ActiveCluster with asynchronous snapshot replication.
Why This Matters:
ActiveCluster:
ActiveCluster provides synchronous replication between two sites within a stretched cluster, ensuring zero RPO and near-zero RTO for high availability.
It is ideal for scenarios where applications require continuous access to data across two locations.
Asynchronous Snapshot Replication:
Asynchronous replication extends the disaster recovery strategy by replicating snapshots to a third site. This ensures an additional layer of protection against regional failures.
Why Not the Other Options?
A. CloudSnap to an offload target:
CloudSnap is used to offload snapshots to cloud storage (e.g., AWS S3 or Azure Blob). While it satisfies the requirement for a third copy, it does not integrate with ActiveCluster for high availability in a stretched cluster.
B. Fan-out asynchronous snapshot replication:
Fan-out replication involves sending snapshots to multiple targets asynchronously. However, it does
not provide the synchronous replication required for a stretched cluster.
C. ActiveDR with periodic snapshot replication:
ActiveDR is designed for asynchronous replication and failover/failback scenarios but does not support synchronous replication for a stretched cluster.
Key Points:
ActiveCluster: Ensures high availability with synchronous replication in a stretched cluster.
Async Replication: Adds a third-site replication target for comprehensive disaster recovery.
Integrated Solution: Combines high availability and disaster recovery into a single architecture.
Reference: Pure Storage FlashArray Documentation: "ActiveCluster with Async Replication"
Pure Storage Whitepaper: "Disaster Recovery Strategies with FlashArray"
Pure Storage Knowledge Base: "Using Protection Groups in Stretched Pods"
정답:
Explanation:
To achieve 100 Gbps of consistent raw network throughput between the FlashArray and the dedicated SAN switches, while ensuring resiliency, the customer must connect a sufficient number of Ethernet ports from the FlashArray to the SAN switches.
Given that the dedicated SAN switches support up to 25 Gbps connectivity per port, the calculation is as follows:
Throughput Requirement:
The customer requires 100 Gbps of raw throughput.
Each Ethernet port provides 25 Gbps of bandwidth.
Number of Ports Needed:
To meet the 100 Gbps requirement:
![]()
Resiliency Requirement:
Resiliency ensures that the solution can tolerate failures (e.g., switch or link failures). To achieve this, the customer must double the number of ports to provide redundant paths.
Therefore, the total number of ports required is:4×2=8ports.
Why Not the Other Options?
B.2:
Two ports would only provide 50 Gbps of raw throughput (2 × 25 Gbps), which does not meet the 100 Gbps requirement. Additionally, there would be no redundancy, violating the resiliency requirement.
C.4:
Four ports would meet the 100 Gbps throughput requirement but would lack redundancy, making the solution vulnerable to failures.
D.16:
Sixteen ports would exceed the required throughput and redundancy, resulting in unnecessary costs and complexity.
Key Points:
Throughput Calculation: Ensure the total bandwidth meets the 100 Gbps requirement.
Resiliency: Double the number of ports to provide redundant paths for high availability.
Optimization: Use the minimum number of ports that satisfy both throughput and resiliency requirements.
Reference: Pure Storage FlashArray Documentation: "Network Design and Configuration Best Practices"
Pure Storage Whitepaper: "NVMe-TCP Connectivity and Performance Optimization"
Pure Storage Knowledge Base: "Calculating Required Network Ports for FlashArray"
정답:
Explanation:
Given that the two FlashArrays are located in different data centers with a network link latency of 35 ms, the best Purity feature to provide protection against a site failure with the lowest recovery point is ActiveDR.
Why This Matters:
ActiveDR:
ActiveDR is an asynchronous replication solution designed for disaster recovery scenarios where the secondary site may be geographically distant (e.g., >10 ms latency).
It provides low RPOs (typically seconds to minutes) and supports fast failover and failback capabilities, ensuring minimal data loss and downtime.
With a 35 ms latency between sites, synchronous replication (e.g., ActiveCluster) is not feasible due to the high latency impacting performance.
Why Not the Other Options?
A. ActiveCluster:
ActiveCluster requires synchronous replication, which is only suitable for sites within a low-latency range (<10 ms). At 35 ms latency, ActiveCluster would cause significant performance degradation.
C. Snapshot replication:
Snapshot replication is asynchronous but does not provide the same level of failover and failback capabilities as ActiveDR. It is better suited for backup purposes rather than disaster recovery with low RPOs.
D. Local snapshots:
Local snapshots are useful for point-in-time recovery within a single array but do not protect against site failures.
Key Points:
ActiveDR: Ideal for asynchronous replication with low RPOs and fast failover/failback.
Latency Considerations: ActiveDR supports higher latencies (e.g., 35 ms) compared to synchronous solutions like ActiveCluster.
Disaster Recovery: Ensures protection against site failures with minimal data loss and downtime.
Reference: Pure Storage FlashArray Documentation: "ActiveDR for Disaster Recovery"
Pure Storage Whitepaper: "Meeting RPO and RTO Requirements with FlashArray"
Pure Storage Knowledge Base: "Choosing the Right Replication Solution for High Latency"
정답:
Explanation:
During a controller upgrade of a Pure Storage FlashArray, the active/active controller architecture ensures there will be no tangible impact on performance. This design allows both controllers to handle I/O operations simultaneously, so even if one controller is being upgraded, the other can continue processing workloads without interruption.
Why This Matters:
Active/Active Architecture: In an active/active design, both controllers share the workload equally. If one controller is taken offline for maintenance or upgrades, the remaining controller seamlessly handles all I/O operations.
This ensures continuous availability and consistent performance during upgrades, minimizing downtime and user impact.
Why Not the Other Options?
B. Stateful controller architecture:
While stateful architectures maintain session information, they do not inherently ensure no performance impact during upgrades. The key factor here is the active/active design.
C. Active/passive controller front-end ports:
In an active/passive design, only one controller is actively handling I/O at any given time. If the active controller is upgraded, the passive controller must take over, which can lead to temporary performance degradation.
D. Primary/secondary controller architecture:
Similar to active/passive, this design relies on a primary controller for all operations, making it less resilient during upgrades compared to active/active.
Key Points:
Active/Active Design: Ensures continuous I/O processing during upgrades.
Seamless Upgrades: Minimizes performance impact and downtime for users.
High Availability: Maintains consistent performance and reliability throughout the upgrade process.
Reference: Pure Storage FlashArray Documentation: "Controller Upgrade Process and Best Practices"
Pure Storage Whitepaper: "Active/Active Controller Architecture"
Pure Storage Knowledge Base: "Minimizing Impact During Controller Upgrades"
정답:
Explanation:
A protection group in a stretched pod should be used for integrating ActiveCluster with asynchronous snapshot replication. This combination allows for synchronous replication within the stretched pod (using ActiveCluster) while also enabling asynchronous replication to a third site for additional disaster recovery protection.
Why This Matters:
ActiveCluster: Provides synchronous replication between two sites within a stretched pod, ensuring
zero RPO and near-zero RTO for high availability.
Async Snapshot Replication: Extends the disaster recovery strategy by replicating snapshots asynchronously to a third site, providing an additional layer of protection against regional failures.
Combining these features ensures both local high availability and remote disaster recovery.
Why Not the Other Options?
B. Using CloudSnap to offload to a third-site target:
CloudSnap is used to offload snapshots to cloud storage (e.g., AWS S3 or Azure Blob). While it is useful for backup purposes, it does not integrate with ActiveCluster for synchronous replication.
C. Initiating ActiveDR failover/failback in a test scenario:
ActiveDR is designed for asynchronous replication and failover/failback scenarios but does not integrate with ActiveCluster in a stretched pod configuration.
D. Configuring fan-out async snapshot replication:
Fan-out replication involves sending snapshots to multiple targets asynchronously. However, this does not align with the use case of integrating ActiveCluster with async replication for a stretched pod.
Key Points:
Stretched Pod: Enables synchronous replication across two sites using ActiveCluster. Async Replication: Adds a third-site replication target for comprehensive disaster recovery. Integrated Protection: Combines high availability and disaster recovery into a single solution.
Reference: Pure Storage FlashArray Documentation: "ActiveCluster with Async Replication"
Pure Storage Whitepaper: "Disaster Recovery Strategies with FlashArray"
Pure Storage Knowledge Base: "Using Protection Groups in Stretched Pods"
정답:
Explanation:
For a customer producing video media content and needing a cost-effective solution to replace their multi-rack HDD-based storage array for video archiving, the best choice is FlashArray//C.
Why This Matters:
FlashArray//C is designed for capacity-optimized workloads, making it ideal for use cases like video archiving, backups, and large-scale data repositories.
It offers high-density storage with QLC flash technology, which provides a balance of performance and cost-effectiveness for less performance-intensive workloads.
Compared to HDD-based systems, FlashArray//C delivers faster access times, lower latency, and improved reliability, all at a lower cost per terabyte than higher-performance arrays like FlashArray//X or //XL.
Why Not the Other Options?
A. FlashArray//X:
FlashArray//X is optimized for high-performance workloads, such as databases and mission-critical applications. While it offers exceptional performance, it is more expensive and not the most cost-effective solution for video archiving.
B. FlashArray//XL:
FlashArray//XL is designed for extreme-scale workloads requiring massive performance and capacity. It is overkill for video archiving and would significantly increase costs without providing proportional benefits.
Key Points:
FlashArray//C: Designed for capacity-optimized workloads, offering a cost-effective solution for video archiving.
QLC Flash Technology: Provides high density and reliability at a lower cost per terabyte compared to traditional HDDs or higher-performance flash arrays.
Cost Efficiency: Balances performance and cost, making it ideal for large-scale, less performance-intensive workloads like video media archives.
Reference: Pure Storage FlashArray//C Documentation: "Use Cases for FlashArray//C"
Pure Storage Whitepaper: "Optimizing Storage Costs with FlashArray//C"
Pure Storage Knowledge Base: "Choosing the Right FlashArray Model for Your Workload"
정답:
Explanation:
Pure Storage's Right-Size Guarantee protects the customer for 12 months starting from the date of arrival. This guarantee ensures that if the customer's storage needs grow beyond their initial purchase, they can upgrade to larger capacity shelves or arrays without overpaying for the additional capacity.
Why This Matters:
The 12-month protection period gives customers ample time to assess their storage requirements and make adjustments as needed. This flexibility is particularly valuable for organizations with dynamic or unpredictable growth patterns.
By protecting the customer for a full year, Pure Storage ensures that they can scale their storage infrastructure efficiently without incurring unnecessary costs.
Why Not the Other Options?
A. 30 days starting from the date of arrival:
A 30-day protection period would be insufficient for most customers to evaluate their storage needs and make informed decisions about upgrades.
B. 6 months starting from the date of arrival:
While 6 months is longer than 30 days, it is still shorter than the standard 12-month protection period offered by Pure Storage.
D. Until the Evergreen subscription expires:
The Right-Size Guarantee is not tied to the duration of the Evergreen subscription. It is specifically valid for 12 months from the date of arrival.
Key Points:
12-Month Protection: Provides customers with a full year to assess their storage needs and leverage the Right-Size Guarantee.
Scalability: Ensures customers can upgrade their storage infrastructure cost-effectively as their needs evolve.
Customer-Centric Approach: Reflects Pure Storage's commitment to delivering flexible and future-proof solutions.
Reference: Pure Storage Evergreen//Forever Documentation: "Right-Size Guarantee Terms and Conditions"
Pure Storage Whitepaper: "Maximizing Value with Evergreen Subscriptions"
Pure Storage Knowledge Base: "Understanding the Right-Size Guarantee Duration"
정답:
Explanation:
The Right-Size Guarantee is an Evergreen//Forever benefit that allows customers to trade in existing storage shelves for newer, higher-capacity shelves while only paying for the incremental capacity increase. In this scenario, the customer can trade in a 12 TB shelf for a 60 TB shelf and only pay for the additional 48 TB of capacity.
Why This Matters:
The Right-Size Guarantee ensures that customers can upgrade their storage infrastructure without overpaying for capacity they already own. This aligns with Pure Storage's commitment to providing flexible and cost-effective storage solutions.
By leveraging this benefit, the customer can modernize their storage environment while optimizing costs.
Why Not the Other Options?
A. Capacity Consolidation:
Capacity Consolidation refers to the ability to consolidate workloads onto fewer arrays or shelves, but it does not specifically address trading in existing shelves for higher-capacity ones at a reduced cost.
B. Flat is Fair Maintenance:
Flat is Fair Maintenance ensures predictable and consistent maintenance pricing over time, but it does not apply to upgrading or trading in storage shelves.
D. Love Your Storage:
Love Your Storage is a program that provides hardware upgrades and enhancements, but it does not directly relate to trading in shelves for capacity increases.
Key Points:
Right-Size Guarantee: Allows customers to trade in existing shelves for higher-capacity shelves at a reduced cost.
Cost Optimization: Ensures customers only pay for the incremental capacity increase, reducing total cost of ownership (TCO).
Evergreen Benefits: Part of Pure Storage's commitment to delivering flexible and future-proof storage solutions.
Reference: Pure Storage Evergreen//Forever Documentation: "Understanding the Right-Size Guarantee"
Pure Storage Whitepaper: "Evergreen Architecture and Subscription Benefits"
Pure Storage Knowledge Base: "How to Leverage the Right-Size Guarantee"
정답:
Explanation:
The exhibit shows latency in the VMware environment connected to the FlashArray. When troubleshooting latency issues in a VMware environment, the first step is to identify whether the issue originates from the storage array, the network, or the ESXi host. In this case, the SE should recommend checking the ESXi host, as it is often the source of latency problems in VMware environments.
Why This Matters:
ESXi Host Issues:
The ESXi host could be experiencing resource contention (e.g., CPU, memory, or network bottlenecks) or misconfigurations (e.g., improper queue depth settings or multipathing policies).
High latency on the ESXi host can impact the performance of virtual machines and appear as storage latency, even if the FlashArray itself is functioning optimally.
Why Not the Other Options?
A. Add DirectFlash Modules as the system is disk bound:
Pure Storage FlashArray uses DirectFlash Modules, which are NVMe-based and provide extremely low latency. If the array were disk-bound, it would indicate a hardware limitation, but this is unlikely with FlashArray's architecture. The issue is more likely related to the ESXi host or network.
B. Upgrade the controllers:
Controller upgrades are typically unnecessary unless the array is nearing its performance limits. Since the exhibit does not indicate any signs of controller saturation, this is not the correct recommendation.
C. Add network cards to alleviate network congestion:
While network congestion can cause latency, the issue is more likely related to the ESXi host configuration. Adding network cards should only be considered after confirming network bottlenecks through diagnostics.
Key Points:
ESXi Host Diagnostics: Start by checking the ESXi host for resource contention, misconfigurations, or improper settings.
Storage Array Health: Verify that the FlashArray is not experiencing any performance issues (e.g., high queue depths or latency).
Network Analysis: Only after ruling out the ESXi host and storage array should network-related issues be investigated.
Reference: Pure Storage FlashArray Documentation: "Troubleshooting Latency in VMware Environments"
VMware Best Practices Guide: "Optimizing ESXi Host Performance"
Pure Storage Knowledge Base: "Diagnosing and Resolving Latency Issues"
정답:
Explanation:
The customer is reviewing their disaster recovery (DR) strategy and wants to replicate data to a secondary datacenter while addressing internal SLAs for RPO (Recovery Point Objective) and RTO (Recovery Time Objective). To meet these requirements, the SE should focus on two key Pure Storage FlashArray features: FlashRecover and ActiveDR.
Why These Features?
FlashRecover:
FlashRecover is a snapshot-based replication feature that allows efficient point-in-time copies of data to be replicated to a secondary site.
It helps achieve low RPOs by enabling frequent snapshots and replication to the DR site. This ensures minimal data loss in the event of a failure. ActiveDR:
ActiveDR is a disaster recovery solution that provides asynchronous replication between two FlashArrays.
It is specifically designed to minimize RTO by enabling fast failover and failback capabilities.
ActiveDR ensures that the secondary site is always ready to take over with minimal downtime, meeting strict RTO requirements.
Why Not the Other Options?
B. ActiveCluster:
ActiveCluster is a synchronous replication solution for high availability across two sites. While it provides zero RPO and near-zero RTO, it requires both sites to be within synchronous distance (typically <10ms latency). Since the customer is replicating to a secondary datacenter (likely farther away), ActiveCluster is not suitable.
C. CloudSnap:
CloudSnap is a feature that offloads snapshots to cloud storage (e.g., AWS S3 or Azure Blob). While it is useful for backup and archival purposes, it does not provide the real-time replication and failover capabilities needed for DR with strict RPO and RTO SLAs.
Key Points:
FlashRecover: Enables efficient replication with low RPOs through snapshot-based replication.
ActiveDR: Provides asynchronous replication with fast failover and failback capabilities to meet RTO requirements.
SLA Alignment: Both features are designed to help customers meet their internal SLAs for RPO and RTO.
Reference: Pure Storage FlashArray Documentation: "Disaster Recovery with FlashRecover and ActiveDR"
Pure Storage Whitepaper: "Meeting RPO and RTO Requirements with FlashArray"
Pure Storage Knowledge Base: "Best Practices for Disaster Recovery Planning"