
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
Qlik Sense Data Architect Certification Exam - 2024 온라인 연습
최종 업데이트 시간: 2025년03월23일
당신은 온라인 연습 문제를 통해 QlikView QSDA2024 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 QSDA2024 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 50개의 시험 문제와 답을 포함하십시오.
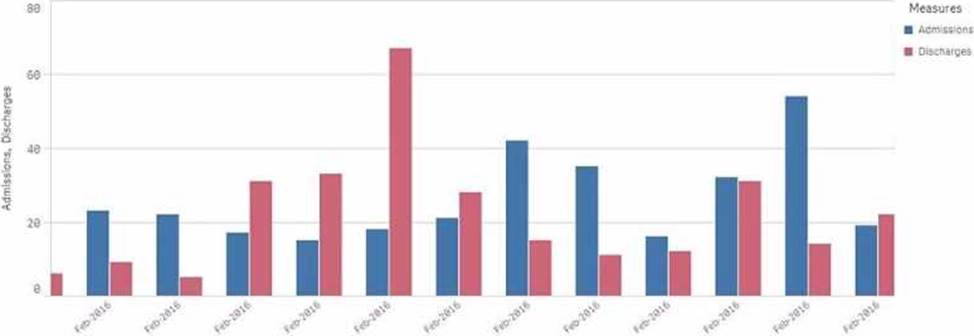
정답:
Explanation:
The issue described relates to the incorrect display of month and year values on the x-axis of a chart. The source data has dates in the M/D/YYYY format, and a calculated field named Month-Year was created using this date format.
To correct the issue:
The correct approach is to use the MonthStart() function, which returns the first date of the month for the provided date. This ensures consistency in month-year representation.
The Date() function is then used to format the result of MonthStart() to the desired format of MMM-YYYY (e.g., Feb-2018).
Explanation of the Correct Expression:
MonthStart([Common Date]): This ensures that all dates within a month are treated as the first day of that month, which is critical for accurate monthly aggregation.
Date(..., 'MMM-YYYY'): This formats the result to show just the month and year in the correct format.
Using this expression ensures that the x-axis correctly displays the month-year values.

정답:
Explanation:
In the provided scenario, the goal is to export tables from a Qlik Sense model based on rules specified in an external text file. The structure of the text file indicates which table to export, the filename to use, and how many copies to create.
Given this structure, the data architect needs to:
Loop through each row in the text file to process each table.
Use an IF statement to check whether the specified table exists in the model (though it's mentioned they are verified to exist, this step may involve conditional logic to ensure the rules are correctly followed).
Use another IF statement to handle the creation of multiple copies, ensuring each file is named incrementally (e.g., Clients1.qvd, Clients2.qvd, etc.).
Key Script Strategies:
Loop: A loop is necessary to iterate through each row of the text file to process the tables specified for export.
IF Statements: The first IF statement checks conditions such as whether the table should be exported (based on additional logic if needed). The second IF statement handles the creation of multiple copies by incrementing the filename.
This approach covers all the necessary logic with the minimum set of scripting strategies, ensuring that each table is exported according to the rules defined.
정답:
Explanation:
In the scenario where the startup company is preparing for an IPO, there is an increased need for meticulous record-keeping, including the recording of variable values used in Qlik Sense applications. The TRACE statement is the most suitable option for logging variable values during script execution.
TRACE: This statement writes custom messages, including variable values, to the script execution log. By using TRACE, you can ensure that every reload log contains the names and current values of all relevant variables, providing the necessary transparency and traceability.
For example, the script could include:
TRACE $(VariableName);
This command will output the variable's value in the script log, ensuring it is recorded for audit purposes.
정답:
Explanation:
In the provided scenario, the sales territories were realigned during the year, and it is necessary to track performance based on the date of the sale and the salesperson’s assignment during that period. The IntervalMatch function is the best approach to create a time-based relationship between the sales transactions and the sales territory assignments.
IntervalMatch: This function is used to match discrete values (e.g., transaction dates) with intervals (e.g., start and end dates for sales territory assignments). By matching the transaction dates with the
intervals in the HR table, you can accurately determine which territory and manager were in effect at the time of each sale.
Using IntervalMatch, you can generate point-in-time data that accurately reflects the dynamic nature of sales territory assignments, allowing both sales reps and regional managers to track performance over time.
정답:
Explanation:
In this scenario, the data architect needs to verify the existence of files before attempting to load them and then proceed accordingly. The correct approach involves using the FileExists() function to check for the presence of each file. If the file exists, the script should execute the file loading routine. The FOR EACH loop will handle multiple files, and the IF statement will control the conditional loading.
FileExists(): This function checks whether a specific file exists at the specified path. If the file exists, it returns TRUE, allowing the script to proceed with loading the file.
FOR EACH: This loop iterates over a list of items (in this case, file paths) and executes the enclosed code for each item.
IF: This statement checks the condition returned by FileExists(). If TRUE, it executes the code block for loading the file; otherwise, it skips to the next iteration.
This combination ensures that the script loads data only if the files are present, optimizing the data loading process and preventing unnecessary errors.
정답: C
Explanation:
In the given data model, there are several issues related to table relationships and key fields that need to be addressed to create a functional and optimized data model. Here's how each step in the chosen solution (Option C) resolves these issues:
Create a key with OrderID and ProductID in the OrderDetails table and in the Shipments table:
By creating a composite key with OrderID and ProductID, you uniquely identify each line item in both the OrderDetails and Shipments tables. This step is crucial for ensuring that each product within an order is correctly associated with its respective shipment.
Delete the ShipmentID in the Orders table:
The ShipmentID in the Orders table is redundant because the Shipments table already captures this information at a more granular level (i.e., at the product level). Removing ShipmentID avoids potential circular references or synthetic keys.
Delete the ProductID and OrderID in the Shipments table:
After creating the composite key in step 1, the individual ProductID and OrderID fields in the Shipments table are no longer necessary for joins. Removing them reduces redundancy and simplifies the table structure.
Concatenate Orders and OrderDetails:
Concatenating Orders and OrderDetails into a single table creates a unified table that contains all necessary order-related information. This helps in simplifying the model and avoiding issues related to managing separate but related tables.
Create a link table using the MasterCalendar table and create a concatenated field between
OrderDate and ShipmentDate:
A link table is created to associate the combined table with the MasterCalendar. By creating a concatenated field that combines OrderDate and ShipmentDate, you ensure that both dates are properly linked to the calendar, allowing for accurate time-based analysis.
정답:
Explanation:
In Qlik Sense, the TRACE statement is used to print custom messages to the script execution log. To output the value of a variable, particularly one that is dynamically assigned, the correct syntax must be used to ensure that the variable's value is evaluated and displayed correctly.
The variable vMaxDate is defined with the LET statement, which means it is evaluated immediately, and its value is stored.
When using the TRACE statement, to output the value of vMaxDate, you need to ensure the variable's value is expanded before being printed. This is done using the $() expansion syntax.
The correct syntax is TRACE #### $(vMaxDate) ####; which evaluates the variable vMaxDate and inserts its value into the log output.
Key Qlik Sense Data Architect
Reference: Variable Expansion: In Qlik Sense scripting, $(variable_name) is used to expand and insert the value of the variable into expressions or statements. This is crucial when you want to output or use the value stored in a variable.
TRACE Statement: The TRACE command is used to write messages to the script log. It is commonly used for debugging purposes to track the flow of script execution or to verify the values of variables during script execution.

정답:
Explanation:
In the scenario where the data model is built with a composite key (keyYearMonthCustNo) to resolve synthetic keys, the following outcomes occur:
Sales and Budget Data Integration:
The composite key ensures that each combination of Year, Month, and Customer is uniquely represented in the combined Sales and Budget data.
During data selection (e.g., when a specific month is selected), Qlik Sense will show all the customer names that have either Sales or Budget data associated with that month.
Resulting Data View:
For the selected month, customers with sales records will display their Sales data. However, if the corresponding Budget data is missing, the Budget column will contain null values.
Similarly, if a customer has a Budget but no Sales data for the selected month, the Sales column will show null values.
Validation Outcome:
When the data architect selects a month, they will see the following:
Customer Names and Sales records for the selected month, where the Sales column will have values and the Budget column may contain null or non-null values depending on the data availability.
정답: D
Explanation:
When dealing with a database that is continuously updated with new records, updates, and deletions, an efficient data load strategy is necessary to minimize the load time and keep the Qlik Sense data model up-to-date.
Explanation of Steps:
Load the existing data from the QVD:
This step retrieves the already loaded and processed data from a previous session. It acts as a base to which new or updated records will be added.
Load new and updated data from the database. Concatenate with the table loaded from the QVD:
The next step is to load only the new and updated records from the database. This minimizes the amount of data being loaded and focuses on just the changes.
The new and updated records are then concatenated with the existing data from the QVD, creating a combined dataset that includes all relevant information.
Create a separate table for the deleted rows and use a WHERE NOT EXISTS to remove these records:
A separate table is created to handle deletions. The WHERE NOT EXISTS clause is used to identify and remove records from the combined dataset that have been deleted in the source database.

정답:
Explanation:
In the script provided, the alt() function is used to handle various date formats. The alt() function in Qlik Sense evaluates a list of expressions and returns the first valid expression. If none of the expressions are valid, it returns the last argument provided (in this case, '31/12/2022').
Step-by-step breakdown:
The alt() function checks the Date field for three different formats:
YYYYMMDD
YYYY/MM/DD
DD/MM/YYYY
If none of these formats match the value in the Date field, the default date '31/12/2022' is assigned.
Values in the Date field:
20210131: Matches the first format YYYYMMDD.
2020/01/31: Matches the second format YYYY/MM/DD.
31/01/2019: Matches the third format DD/MM/YYYY.
9999: Does not match any of the formats, so the alt() function returns the default value '31/12/2022'.
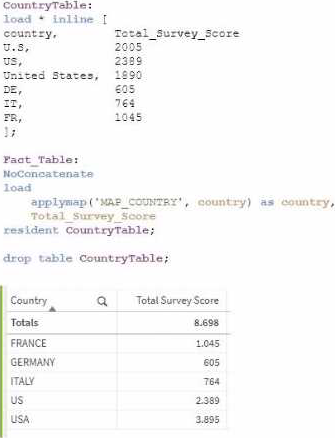
정답:
Explanation:
In this scenario, the issue arises from using the applymap() function to normalize the country field values, but the result is incorrect. The reason is most likely related to the values in the source mapping table not matching the values in the Fact_Table properly.
The applymap() function in Qlik Sense is designed to map one field to another using a mapping table. If the source values in the mapping table are inconsistent or incorrect, the applymap() will not function as expected, leading to incorrect results.
Steps to resolve:
Review the mapping table (MAP_COUNTRY): The country field in the CountryTable contains values such as "U.S.", "US", and "United States" for the same country. To correctly normalize the country names, you need to ensure that all variations of a country's name are consistently mapped to a single value (e.g., "USA").
Apply Mapping: Review and clean up the mapping table so that all possible variants of a country are correctly mapped to the desired normalized value.
Key
Reference: Mapping Tables in Qlik Sense: Mapping tables allow you to substitute field values with mapped values. Any mismatches or variations in source values should be thoroughly reviewed.
Applymap() Function: This function takes a mapping table and applies it to substitute a field value with its mapped equivalent. If the mapped values are not correct or incomplete, the output will not
be as expected.
정답:
Explanation:
When retrieving data from a REST API, particularly when the dataset is large or the data is segmented across multiple pages (which is common in REST APIs), the REST Connector in Qlik Sense needs to be configured to handle pagination.
Pagination is the process of dividing the data retrieved from the API into pages that can be loaded sequentially or as required. Qlik Sense's REST Connector supports pagination by allowing the data architect to set parameters that will sequentially retrieve each page of data, ensuring that the complete dataset is retrieved.
Key Steps:
REST Connector Setup: Configure the REST connector in Qlik Sense and specify the necessary API endpoint.
Pagination Mechanism: Use the built-in pagination mechanism to define how the connector should retrieve the subsequent pages (e.g., by using query parameters like page or offset).
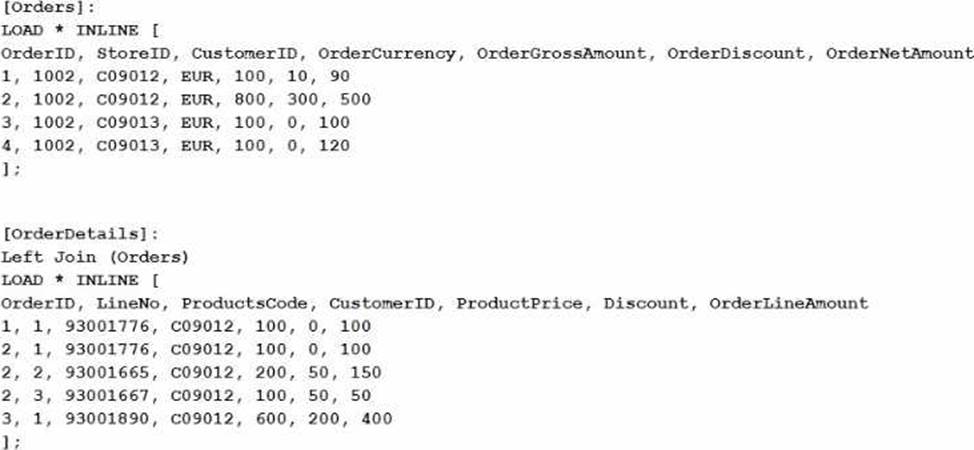
정답:
Explanation:
The expression sum([OrderNetAmount]) sums the values in the OrderNetAmount field across the dataset. Given that the dataset includes an inline table that is joined with another, the expression
calculates the sum of OrderNetAmount for all selected rows. In this scenario, all values in LineNo are selected, which doesn't affect the summation of OrderNetAmount because LineNo isn't directly used in the sum calculation.
Step-by-step Calculation:
The Orders table contains the OrderNetAmount for each order. The values provided are 90, 500, 100, and 120.
Adding these values together:
90+500+100+120=81090 + 500 + 100 + 120 = 81090+500+100+120=810
However, after the Left Join operation with the OrderDetails table, some of these rows might be duplicated if the join results in multiple matches. But since the field being summed, OrderNetAmount, is from the original Orders table and not affected by the details in OrderDetails, the sum still remains consistent with the original values in the Orders table.
Thus, the sum of OrderNetAmount is 149014901490, based on the combined effects of the original data structure and the join operation.
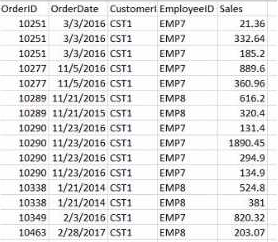
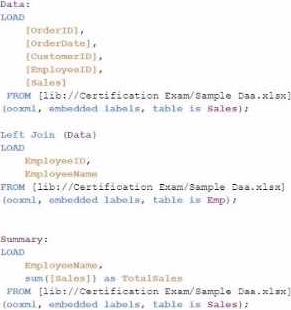
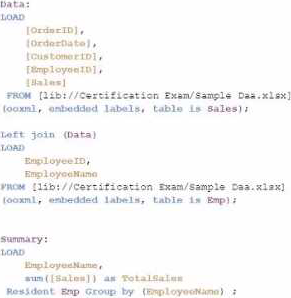
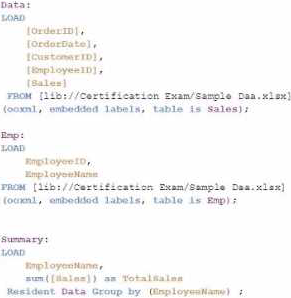
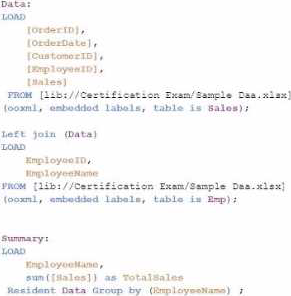
정답:
Explanation:
The goal is to display the aggregated sales for each sales representative, with all aggregations being performed in the script. Option C is the correct choice because it performs the aggregation correctly using a Group by clause, ensuring that the sum of sales for each employee is calculated within the script.
Data Load:
The Data table is loaded first from the Sales table. This includes the OrderID, OrderDate, CustomerID, EmployeeID, and Sales.
Next, the Emp table is loaded containing EmployeeID and EmployeeName.
Joining Data:
A Left Join is performed between the Data table and the Emp table on EmployeeID, enriching the data with EmployeeName.
Aggregation:
The Summary table is created by loading the EmployeeName and calculating the total sales using the sum([Sales]) function.
The Resident keyword indicates that the data is pulled from the existing tables in memory, specifically the Data table.
The Group by clause ensures that the aggregation is performed correctly for each EmployeeName, summarizing the total sales for each employee.
Key Qlik Sense Data Architect
Reference: Resident Load: This is a method to reuse data that is already loaded into the app’s memory. By using a Resident load, you can create new tables or perform calculations like aggregation on the existing data.
Group by Clause: The Group by clause is essential when performing aggregations in the script. It groups the data by specified fields and performs the desired aggregation function (e.g., sum, count).
Left Join: Used to combine data from two tables. In this case, Left Join is used to enrich the sales data with employee names, ensuring that the sales data is associated correctly with the respective employee.
Conclusion: Option C is the most appropriate script for this task because it correctly performs the necessary joins and aggregations in the script. This ensures that the dashboard will display the correct aggregated sales per employee, meeting the data architect’s requirements.
정답:
Explanation:
In Qlik Sense, when a data load script is executed and an error occurs, the script execution is halted immediately, and any tables that were being loaded at the time of the error are discarded. However, the existing data model―i.e., the last successfully loaded data model―remains intact and is not affected by the failed script. This ensures that the application retains the last known good state of the data, avoiding any partial or inconsistent data loads that could occur due to an error.
When the script encounters an error:
The tables that were successfully loaded prior to the error are retained in the session, but these tables are not merged with the existing data model.
The existing data model before the script was executed remains unchanged and is maintained.
No partial or incomplete data is loaded into the application; hence, the data model remains consistent and reliable.
Qlik Sense Data Architect Reference
This behavior is designed to protect the integrity of the data model. In scenarios where script execution fails, the user can debug and fix the script without risking the data integrity of the existing application. The key references include:
Qlik Help Documentation: Provides detailed information on how Qlik Sense handles script errors, highlighting that the existing data model remains unchanged after an error.
Data Load Editor Practices: Best practices dictate ensuring that the script is fully functional before executing it to avoid data inconsistency. In cases where an error occurs, understanding that the current data model is maintained helps in strategic debugging and script correction